上一篇讲解了《增广拉格朗日方法求解带约束优化问题》,套路是外层ALM和内层ilqr进行无约束优化。内层可以用ilqr做无约束优化问题求解,那么可以用其他方法求解吗?答案是可以的,如lbfgs也可以用于无约束优化问题。
恰好最近看到一篇论文,用的是ALM(增广拉格朗日法)+LBFGS(拟牛顿法),下边让我们来看一下。
让人兴奋的一点是,论文里提到:
一个统一的轨迹可以同时处理前进和后退运动,而不是由规划前端指定
这里无需前端提供换挡点,也就是无需混合a星来提供初始解。那这不就是直接革了hybrid a star的命了嘛。让我们来仔细的学习这篇文章,看一看到底是怎么回事。后续要结合开源代码看一下实际效果。
这篇论文提出了一个面向差速驱动机器人(包括轮式与履带式)的统一轨迹优化框架。作者基于瞬时旋转中心(ICR)建立通用运动学模型,并用运动状态表示法(在姿态与弧长空间构造多段多项式轨迹)使轨迹天然满足连续性和运动学约束。在约束处理上,论文创新性地结合了惩罚函数(处理速度、加速度、安全等不等式约束)与增广拉格朗日方法(仅处理终点位置等式约束),既保证了精度又提高了数值稳定性。
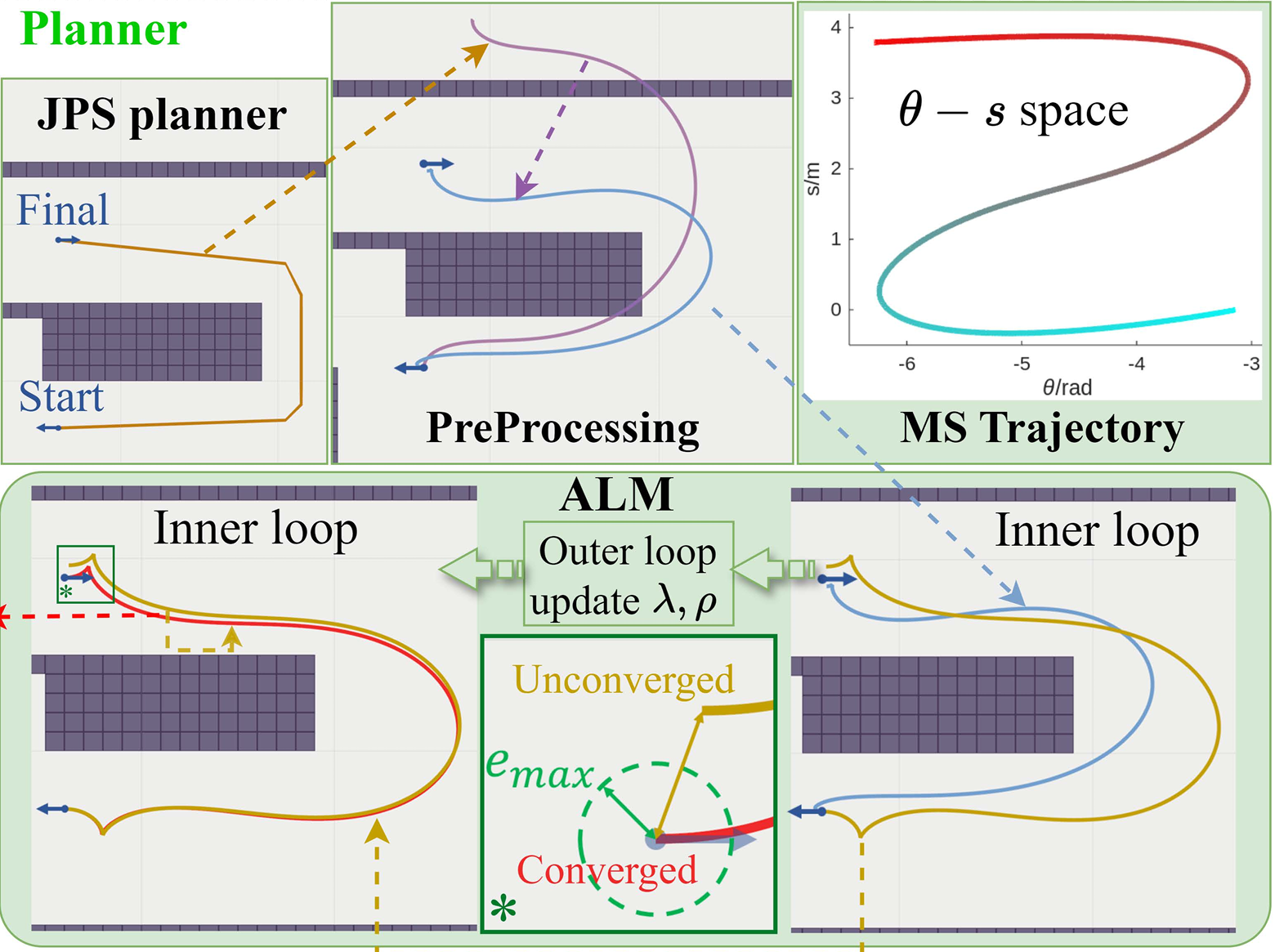
算法的示意图如下,非常有意思的研究,其中的一些处理技巧,可以在自己的工作中灵活应用,建议收藏和点赞,有空再看!
1.轨迹表示
在本节中,我们重点介绍一种基于运动状态多项式参数化的全新轨迹表示方法。
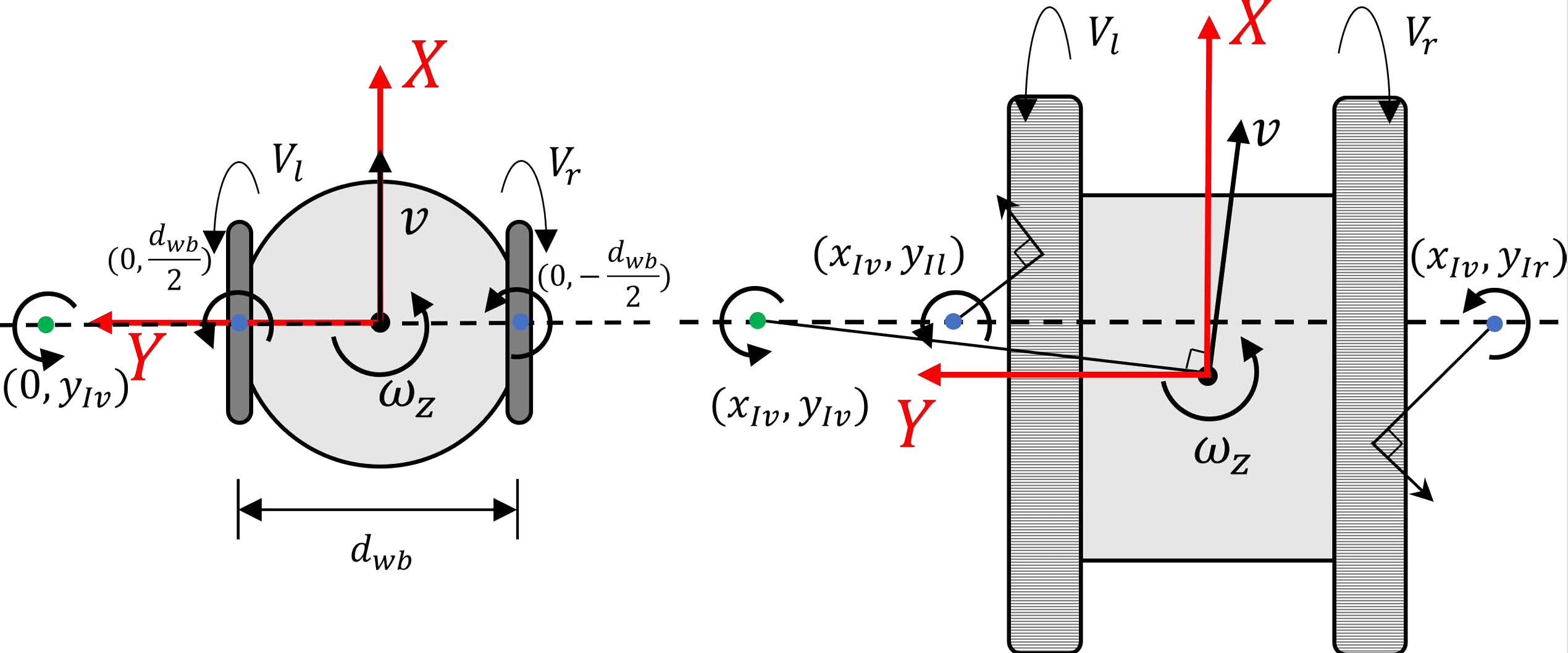
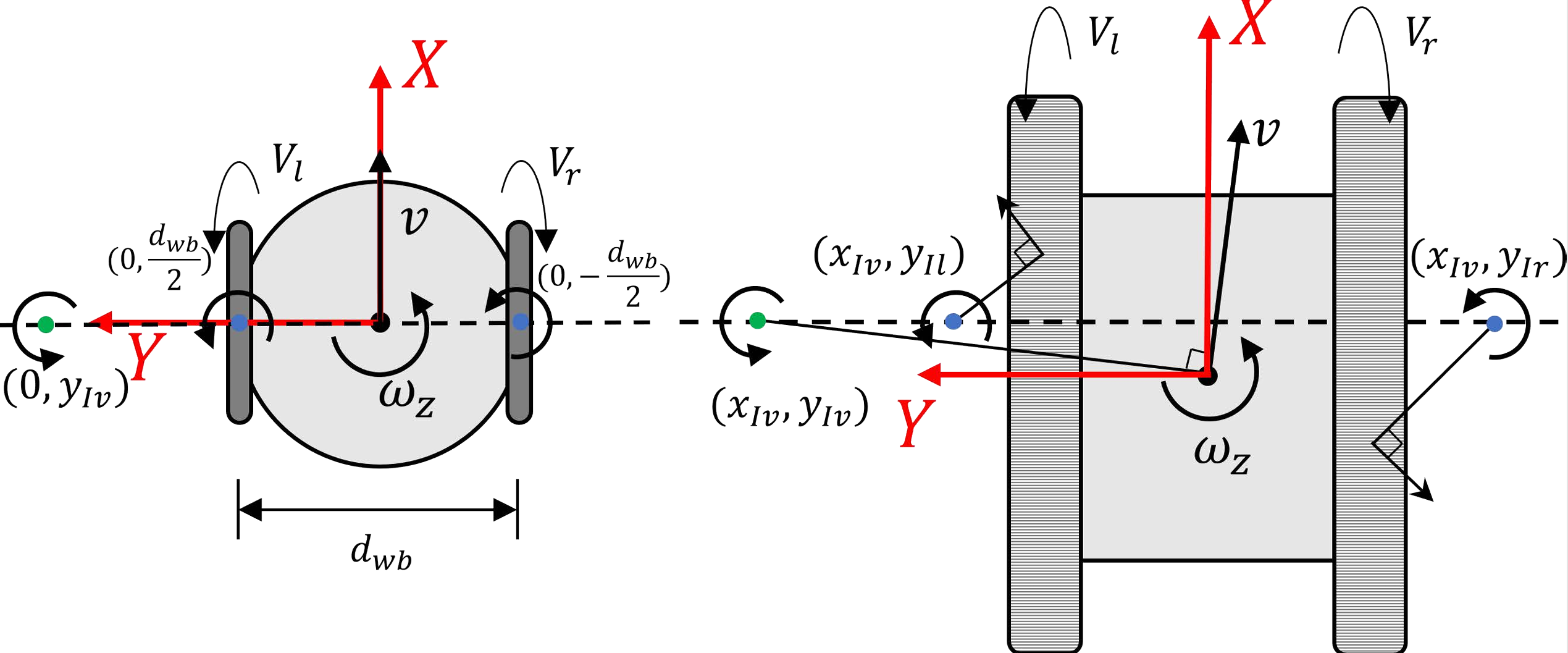
A. 差分驱动机器人的运动学模型
绿色点:表示机器人机体的瞬时旋转中心(ICR of body)。
蓝色点:表示左右驱动轮或履带与地面的接触点的 ICR。
机体坐标系:
原点在几何中心(两轮中点或履带几何中心)。
x 轴:与机器人前进方向对齐。
y 轴:与车体横向方向对齐。
我们采用 瞬时旋转中心(Instantaneous Centers of Rotation, ICRs) [1] 来描述差分驱动机器人的运动,如图 3 所示。通过引入 ICR,可以方便地将机器人几何中心定义为机体坐标系的原点,并使 x 轴与机器人朝向保持一致。此时,机器人的瞬时平移与旋转速度可以表示为:
ω = V r − V l y I l − y I r , (1) \omega = \frac{V_r - V_l}{y_{Il} - y_{Ir}}, \tag{1} ω = y I l − y I r V r − V l , ( 1 )
ω \omega ω V r , V l V_r, V_l V r , V l y I l , y I r y_{Il}, y_{Ir} y I l , y I r 含义:角速度由左右轮速差决定,并与轮距(y I l − y I r y_{Il}-y_{Ir} y I l − y I r
v x = V r + V l 2 − V r − V l y I l − y I r ⋅ ( y I l + y I r 2 ) , (2) v_x = \frac{V_r + V_l}{2} - \frac{V_r - V_l}{y_{Il} - y_{Ir}} \cdot \left(\frac{y_{Il} + y_{Ir}}{2}\right), \tag{2} v x = 2 V r + V l − y I l − y I r V r − V l ⋅ ( 2 y I l + y I r ) , ( 2 )
v x v_x v x V r + V l 2 \frac{V_r + V_l}{2} 2 V r + V l V r − V l y I l − y I r \frac{V_r - V_l}{y_{Il} - y_{Ir}} y I l − y I r V r − V l ω \omega ω y I l + y I r 2 \frac{y_{Il} + y_{Ir}}{2} 2 y I l + y I r 含义:纵向速度不仅取决于左右轮速度的平均值,还受到旋转引起的几何中心偏移的影响。
v y = − V r − V l y I l − y I r , x I v = − ω x I v . (3) v_y = -\frac{V_r - V_l}{y_{Il} - y_{Ir}}, \quad x_{Iv} = -\omega x_{Iv}. \tag{3} v y = − y I l − y I r V r − V l , x I v = − ω x I v . ( 3 )
v y v_y v y
对于标准两轮差速车(SDD),v y = 0 v_y = 0 v y = 0
对于滑移转向或履带机器人(SKDD/TDD),由于接触点与几何中心存在偏差,v y ≠ 0 v_y \neq 0 v y = 0
x I v x_{Iv} x I v x I v = − ω x I v x_{Iv} = -\omega x_{Iv} x I v = − ω x I v
对于 SDD 机器人,其车轮的 ICR 位于与地面的接触点,满足 y I l = − y I r = d w b / 2 y_{Il} = -y_{Ir} = d_{wb}/2 y I l = − y I r = d w b /2 d w b d_{wb} d w b x I v = 0 x_{Iv} = 0 x I v = 0
B. 运动状态轨迹
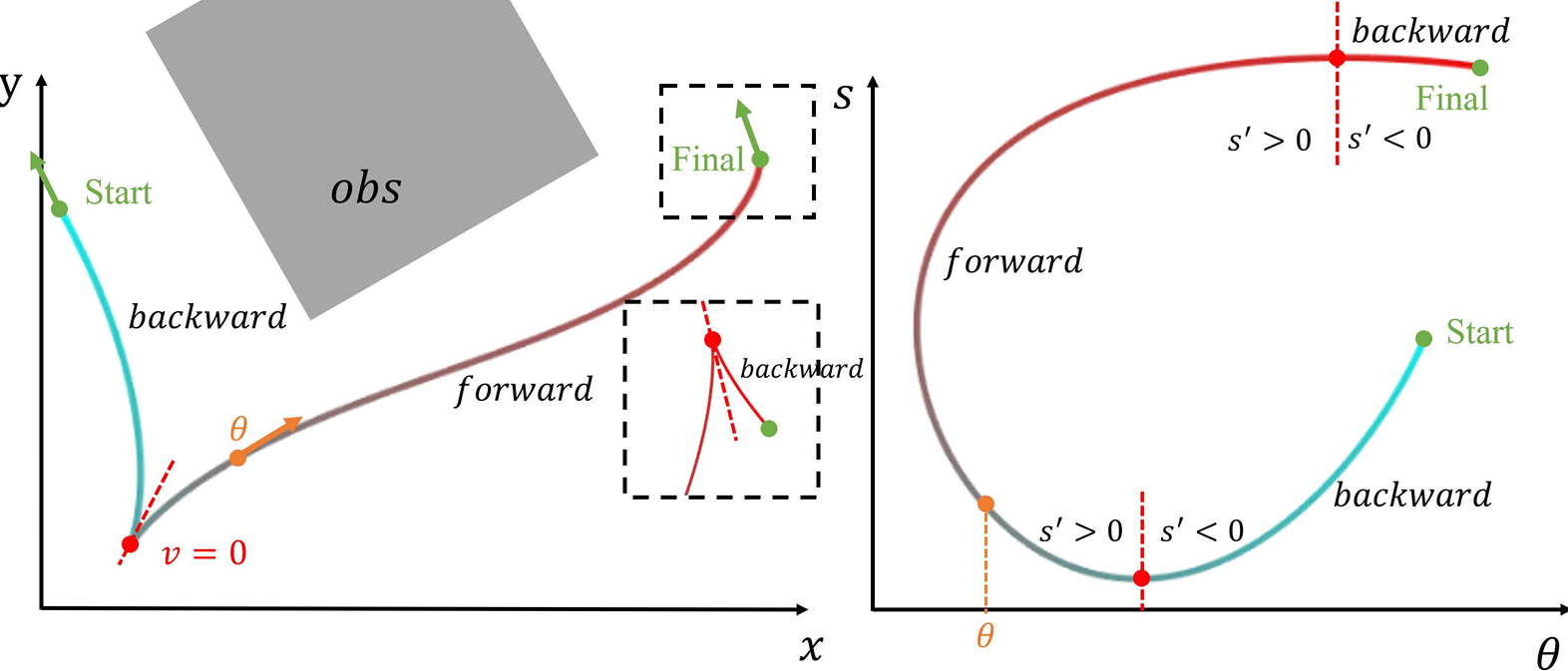
在移动机器人规划中,常见的做法是直接在平面坐标 ( x , y ) (x,y) ( x , y )
一旦轨迹包含前进/后退切换,轨迹在 ( x , y ) (x,y) ( x , y )
控制器在跟踪这些轨迹时会不稳定。
解决思路:换一种表达方式。我们不直接画 ( x , y ) (x,y) ( x , y ) θ ( t ) \theta(t) θ ( t ) s ( t ) s(t) s ( t ) ( x , y ) (x,y) ( x , y )
这种方法被称为 运动状态轨迹 (Motion State Trajectory, MS Trajectory)。
(1) 如何表示一条轨迹?
我们把轨迹分成多段,每一段的朝向角和前进弧长,都用 时间多项式 来表示:
θ ( t ) = β ⊤ ( t ) c θ , s ( t ) = β ⊤ ( t ) c s \theta(t) = \beta^\top(t) c_{\theta}, \quad s(t) = \beta^\top(t) c_{s} θ ( t ) = β ⊤ ( t ) c θ , s ( t ) = β ⊤ ( t ) c s 这里:
θ ( t ) \theta(t) θ ( t ) s ( t ) s(t) s ( t ) β ( t ) = [ 1 , t , t 2 , … , t 2 h − 1 ] T \beta(t) = [1, t, t^2, \dots, t^{2h-1}]^T β ( t ) = [ 1 , t , t 2 , … , t 2 h − 1 ] T c θ , c s c_{\theta}, c_{s} c θ , c s
重要导数:
s ˙ ( t ) = v x ( t ) \dot s(t) = v_x(t) s ˙ ( t ) = v x ( t ) θ ˙ ( t ) = ω ( t ) \dot \theta(t) = \omega(t) θ ˙ ( t ) = ω ( t ) ( θ , s ) (\theta, s) ( θ , s )
(2) 如何还原平面位置?
虽然轨迹在 ( θ , s ) (\theta,s) ( θ , s ) ( x , y ) (x,y) ( x , y )
x ( t ) = x 0 + ∫ 0 t [ s ˙ ( τ ) cos θ ( τ ) + x I v θ ˙ ( τ ) sin θ ( τ ) ] d τ y ( t ) = y 0 + ∫ 0 t [ s ˙ ( τ ) sin θ ( τ ) − x I v θ ˙ ( τ ) cos θ ( τ ) ] d τ \begin{aligned}
x(t) &= x_0 + \int_{0}^{t} \left[ \dot s(\tau)\cos\theta(\tau) + x_{Iv}\,\dot\theta(\tau)\sin\theta(\tau) \right] d\tau \\
y(t) &= y_0 + \int_{0}^{t} \left[ \dot s(\tau)\sin\theta(\tau) - x_{Iv}\,\dot\theta(\tau)\cos\theta(\tau) \right] d\tau
\end{aligned} x ( t ) y ( t ) = x 0 + ∫ 0 t [ s ˙ ( τ ) cos θ ( τ ) + x I v θ ˙ ( τ ) sin θ ( τ ) ] d τ = y 0 + ∫ 0 t [ s ˙ ( τ ) sin θ ( τ ) − x I v θ ˙ ( τ ) cos θ ( τ ) ] d τ 解释:
( x 0 , y 0 ) (x_0,y_0) ( x 0 , y 0 ) s ˙ cos θ , s ˙ sin θ \dot s \cos\theta, \dot s \sin\theta s ˙ cos θ , s ˙ sin θ x I v x_{Iv} x I v 当机器人转弯时,如果有横滑,就会额外产生位移,这由 x I v θ ˙ x_{Iv}\dot\theta x I v θ ˙
(3) 如何计算积分?
直接算上面的积分很难,所以引入 Simpson 公式 来近似:
∫ a b f ( x ) d x ≈ b − a 6 [ f ( a ) + 4 f ( a + b 2 ) + f ( b ) ] \int_a^b f(x)\, dx \;\approx\; \frac{b-a}{6} \left[ f(a) + 4f\!\left(\tfrac{a+b}{2}\right) + f(b) \right] ∫ a b f ( x ) d x ≈ 6 b − a [ f ( a ) + 4 f ( 2 a + b ) + f ( b ) ] 通俗的解释:
在区间的左端点、中点、右端点各取一个采样值。
用权重 1 : 4 : 1 1:4:1 1 : 4 : 1
这种方法既快又准,非常适合轨迹优化中实时计算。
(4) 整条轨迹的数值积分
先分段:整条轨迹切成 M M M
再分小区间:每段再切成 n n n x 位移 = ∫ [ s ˙ cos θ + x I v θ ˙ sin θ ] d t . x\text{ 位移}=\int \big[\dot s\cos\theta + x_{Iv}\dot\theta\sin\theta\big]\,dt. x 位移 = ∫ [ s ˙ cos θ + x I v θ ˙ sin θ ] d t .
每个小区间只看三个点:左端、中点、右端,函数值按权重 1 : 4 : 1 1:4:1 1 : 4 : 1 1 6 \frac{1}{6} 6 1
把所有小块加起来:得到该段的近似位移 x i x_i x i x i x_i x i x 0 x_0 x 0 x x x
为什么可行:Simpson 对平滑函数很准,且误差随 n 4 n^4 n 4
一条轨迹通常分为 M M M n n n
x ~ f = ∑ i = 1 M x i ( c i , T i ) + x 0 \tilde{x}_f \;=\; \sum_{i=1}^{M} x_i(c_i, T_i) \;+\; x_0 x ~ f = i = 1 ∑ M x i ( c i , T i ) + x 0 每段的复合 Simpson 近似:
x i ( c i , T i ) = T i 6 n ∑ j = 1 n ( x ^ i j , 0 + 4 x ^ i j , 1 + x ^ i j , 2 ) x_i(c_i, T_i) \;=\; \frac{T_i}{6n}\sum_{j=1}^{n}
\Big(\hat{x}_i^{\,j,0}+4\hat{x}_i^{\,j,1}+\hat{x}_i^{\,j,2}\Big)
x i ( c i , T i ) = 6 n T i j = 1 ∑ n ( x ^ i j , 0 + 4 x ^ i j , 1 + x ^ i j , 2 ) 每个小区间的 integrand(被积函数在采样点的值):
x ^ i j , l = s ˙ ( T i j , l ) cos ( θ i ( T i j , l ) ) + x I v θ ˙ i ( T i j , l ) sin ( θ i ( T i j , l ) ) , l = 0 , 1 , 2 \hat{x}_i^{\,j,l}
= \dot s\!\big(T_i^{\,j,l}\big)\cos\!\big(\theta_i(T_i^{\,j,l})\big)
+ x_{Iv}\,\dot\theta_i(T_i^{\,j,l})\sin\!\big(\theta_i(T_i^{\,j,l})\big),
\qquad l=0,1,2 x ^ i j , l = s ˙ ( T i j , l ) cos ( θ i ( T i j , l ) ) + x I v θ ˙ i ( T i j , l ) sin ( θ i ( T i j , l ) ) , l = 0 , 1 , 2 采样时刻(每段时间网格):
T i j , l = 2 ( j − 1 ) + l 2 n T i , j = 1 , … , n , l = 0 , 1 , 2 T_i^{\,j,l} \;=\; \frac{2(j-1)+l}{2n}\,T_i,
\qquad j=1,\dots,n,\; l=0,1,2 T i j , l = 2 n 2 ( j − 1 ) + l T i , j = 1 , … , n , l = 0 , 1 , 2
M M M M M M i ∈ { 1 , … , M } i \in \{1,\dots,M\} i ∈ { 1 , … , M } i i i T i T_i T i i i i n n n j ∈ { 1 , … , n } j \in \{1,\dots,n\} j ∈ { 1 , … , n } i i i l ∈ { 0 , 1 , 2 } l \in \{0,1,2\} l ∈ { 0 , 1 , 2 } l = 0 l=0 l = 0 l = 1 l=1 l = 1 l = 2 l=2 l = 2 T i j , l = 2 ( j − 1 ) + l 2 n T i T_i^{\,j,l}=\dfrac{2(j-1)+l}{2n}\,T_i T i j , l = 2 n 2 ( j − 1 ) + l T i i i i j j j l l l
等价理解:把第 i i i [ 0 , T i ] [0,T_i] [ 0 , T i ] 2 n 2n 2 n t i , k = k ⋅ T i 2 n t_{i,k}=k\cdot\frac{T_i}{2n} t i , k = k ⋅ 2 n T i
左端点 T i j , 0 = t i , 2 j − 2 T_i^{\,j,0}=t_{i,2j-2} T i j , 0 = t i , 2 j − 2
中点 T i j , 1 = t i , 2 j − 1 T_i^{\,j,1}=t_{i,2j-1} T i j , 1 = t i , 2 j − 1
右端点 T i j , 2 = t i , 2 j T_i^{\,j,2}=t_{i,2j} T i j , 2 = t i , 2 j
x 0 x_0 x 0 x ~ f \tilde{x}_f x ~ f ( ⋅ ) ~ \tilde{(\cdot)} ( ⋅ ) ~ x i ( c i , T i ) x_i(c_i,T_i) x i ( c i , T i ) i i i c i c_i c i θ \theta θ s s s T i T_i T i x ^ i j , l \hat{x}_i^{\,j,l} x ^ i j , l f ( t ) f(t) f ( t ) T i j , l T_i^{\,j,l} T i j , l x ^ i j , l = s ˙ ( T i j , l ) cos ( θ i ( T i j , l ) ) + x I v θ ˙ i ( T i j , l ) sin ( θ i ( T i j , l ) ) . \hat{x}_i^{\,j,l}
= \dot s\!\big(T_i^{\,j,l}\big)\cos\!\big(\theta_i(T_i^{\,j,l})\big)
+ x_{Iv}\,\dot\theta_i(T_i^{\,j,l})\sin\!\big(\theta_i(T_i^{\,j,l})\big). x ^ i j , l = s ˙ ( T i j , l ) cos ( θ i ( T i j , l ) ) + x I v θ ˙ i ( T i j , l ) sin ( θ i ( T i j , l ) ) . s ˙ ( t ) \dot s(t) s ˙ ( t ) s ( t ) s(t) s ( t ) θ i ( t ) \theta_i(t) θ i ( t ) θ ˙ i ( t ) \dot\theta_i(t) θ ˙ i ( t ) i i i x I v x_{Iv} x I v
(5) 为什么 ( θ , s ) (\theta,s) ( θ , s )
如果直接在 ( x , y ) (x,y) ( x , y ) ( θ , s ) (\theta,s) ( θ , s )
前进/后退只需要改变 s ( t ) s(t) s ( t )
整条轨迹依旧是光滑曲线。
这也是论文中图4所展示的核心对比:
红点:在 ( x , y ) (x,y) ( x , y )
平滑曲线:在 ( θ , s ) (\theta,s) ( θ , s )
2. 轨迹优化问题
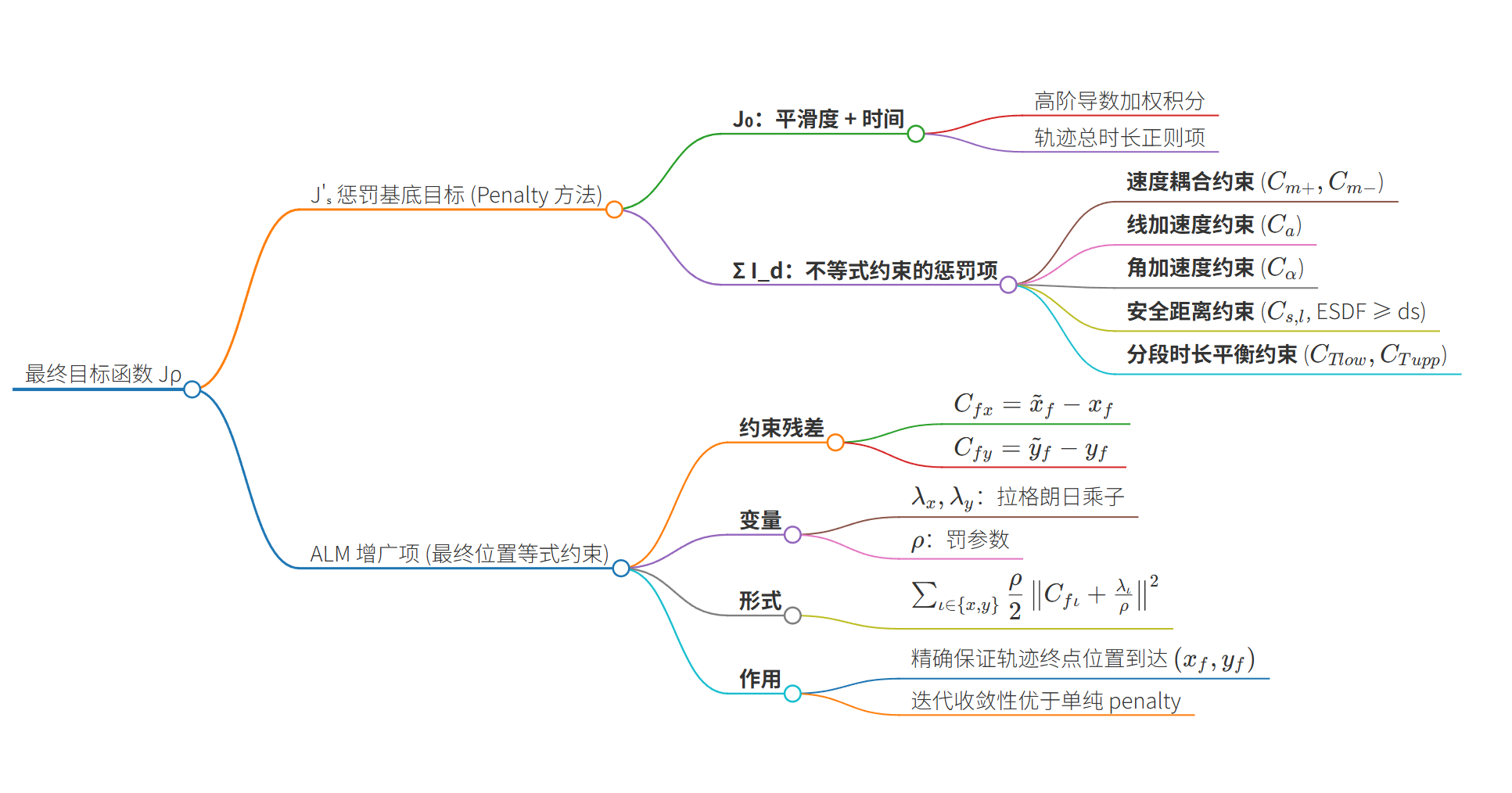
接下来让我们基于 MS 轨迹表示 构建轨迹优化问题。 先看一下最终的目标函数:
J ρ ( w σ ′ , τ , s f , λ ) = J s ′ ⏟ 惩罚基底目标 + ∑ ι ∈ { x , y } ρ 2 ∥ C f ι ( c ( w σ ′ , τ , s f ) , T ( τ ) ) + λ ι ρ ∥ 2 ⏟ ALM 增广:仅用于终点位置等式约束 \boxed{
J_{\rho}\!\left(w_{\sigma'},\,\tau,\,s_f,\,\lambda\right)
=
\underbrace{J'_s}_{\text{惩罚基底目标}}
\;+\;
\underbrace{\sum_{\iota\in\{x,y\}}\frac{\rho}{2}\,\left\|
C_{f\iota}\!\big(c(w_{\sigma'},\tau,s_f),\,T(\tau)\big)+\frac{\lambda_\iota}{\rho}
\right\|^2}_{\text{ALM 增广:仅用于终点位置等式约束}}
} J ρ ( w σ ′ , τ , s f , λ ) = 惩罚基底目标 J s ′ + ALM 增广:仅用于终点位置等式约束 ι ∈ { x , y } ∑ 2 ρ C f ι ( c ( w σ ′ , τ , s f ) , T ( τ ) ) + ρ λ ι 2 将目标展开是这样的:
J ρ ( w σ ′ , τ , s f , λ ) = ( ∫ 0 ∑ i T i ( τ ) σ ( h ) ( t ) ⊤ W σ ( h ) ( t ) d t + ε T ∑ i T i ( τ ) ⏟ J 0 平滑度+时间代价 + ∑ d ς d ∑ i = 1 M ∑ j = 0 n T i ( τ ) n ν j L 1 ( C d i , j ( c ( w σ ′ , τ , s f ) , T ( τ ) ) ) ⏟ ∑ I d 不等式约束的惩罚项 ) ⏟ J s ′ 惩罚基底目标 + ∑ ι ∈ { x , y } ρ 2 ∥ p ~ f , ι ( c ( w σ ′ , τ , s f ) , T ( τ ) ) − p f , ι ⏟ C f ι 终点位置残差 + λ ι ρ ∥ ALM 增广项 2 \begin{aligned}
J_{\rho}(w_{\sigma'},\tau,s_f,\lambda)
&=
\underbrace{\Big(
\underbrace{\int_{0}^{\sum_i T_i(\tau)}\!\!\sigma^{(h)}(t)^{\!\top}
W\sigma^{(h)}(t)\,dt+\varepsilon_T\sum_i T_i(\tau)}_{J_0 \;\;\;\;\text{平滑度+时间代价}}
\;+\;
\underbrace{\sum_{d}\varsigma_d\sum_{i=1}^{M}\sum_{j=0}^{n}
\tfrac{T_i(\tau)}{n}\nu_j\,L_1\big(C^{\,i,j}_d(c(w_{\sigma'},\tau,s_f),T(\tau))\big)}_{\sum I_d \;\;\;\;\text{不等式约束的惩罚项}}
\Big)}_{J'_s \;\;\;\;\text{惩罚基底目标}}
\\
&\quad+\;
\sum_{\iota\in\{x,y\}}
\frac{\rho}{2}\,
\left\|
\underbrace{\tilde{p}_{f,\iota}(c(w_{\sigma'},\tau,s_f),T(\tau)) - p_{f,\iota}}_{C_{f\iota}\;\;\;\;\text{终点位置残差}}
+\frac{\lambda_\iota}{\rho}
\right\|^2_{\;\;\;\;\text{ALM 增广项}}
\end{aligned} J ρ ( w σ ′ , τ , s f , λ ) = J s ′ 惩罚基底目标 ( J 0 平滑度 + 时间代价 ∫ 0 ∑ i T i ( τ ) σ ( h ) ( t ) ⊤ W σ ( h ) ( t ) d t + ε T i ∑ T i ( τ ) + ∑ I d 不等式约束的惩罚项 d ∑ ς d i = 1 ∑ M j = 0 ∑ n n T i ( τ ) ν j L 1 ( C d i , j ( c ( w σ ′ , τ , s f ) , T ( τ )) ) ) + ι ∈ { x , y } ∑ 2 ρ C f ι 终点位置残差 p ~ f , ι ( c ( w σ ′ , τ , s f ) , T ( τ )) − p f , ι + ρ λ ι ALM 增广项 2 下边我们开始逐步讲解优化问题如何得到的。
A. 轨迹优化问题的形式化
基于前面提出的新型轨迹表示,我们构造优化问题如下:
min c , T J 0 = ∫ 0 T s σ ( h ) ( t ) T W σ ( h ) ( t ) d t + ϵ T T s (10a) \min_{c,T} J_0 = \int_0^{T_s} \sigma^{(h)}(t)^T W \sigma^{(h)}(t) \, dt + \epsilon_T T_s \tag{10a} c , T min J 0 = ∫ 0 T s σ ( h ) ( t ) T W σ ( h ) ( t ) d t + ϵ T T s ( 10a )
c c c T = [ T 1 , … , T M ] T T=[T_1,\dots,T_M]^T T = [ T 1 , … , T M ] T σ ( h ) ( t ) = [ θ ( h ) ( t ) , s ( h ) ( t ) ] T \sigma^{(h)}(t)=[\theta^{(h)}(t),\; s^{(h)}(t)]^T σ ( h ) ( t ) = [ θ ( h ) ( t ) , s ( h ) ( t ) ] T θ \theta θ s s s h h h h = 3 h=3 h = 3 W ∈ R 2 × 2 W\in\mathbb{R}^{2\times 2} W ∈ R 2 × 2 ϵ T > 0 \epsilon_T>0 ϵ T > 0 含义:让高阶导数小(轨迹更平滑),同时抑制时长过大。
约束条件为:
(1) 初始条件:
σ [ h − 1 ] ( 0 ) = σ 0 [ h − 1 ] (10b) \sigma^{[h-1]}(0) = \sigma^{[h-1]}_0 \tag{10b} σ [ h − 1 ] ( 0 ) = σ 0 [ h − 1 ] ( 10b ) 这里就相当于在笛卡尔系时,我们指定起点的位置,加速度等起始条件。这里用的是朝向θ \theta θ s s s
σ [ h − 1 ] ( t ) \sigma^{[h-1]}(t) σ [ h − 1 ] ( t ) h − 1 h\!-\!1 h − 1 σ [ h − 1 ] = [ θ , θ ˙ , … , θ ( h − 1 ) , s , s ˙ , … , s ( h − 1 ) ] T \sigma^{[h-1]}=[\theta,\dot\theta,\dots,\theta^{(h-1)},\; s,\dot s,\dots,s^{(h-1)}]^T σ [ h − 1 ] = [ θ , θ ˙ , … , θ ( h − 1 ) , s , s ˙ , … , s ( h − 1 ) ] T σ 0 [ h − 1 ] \sigma^{[h-1]}_0 σ 0 [ h − 1 ] s 0 = 0 s_0\!=\!0 s 0 = 0
(2) 终止条件:
θ [ h − 1 ] ( T s ) = θ f [ h − 1 ] , s [ h − 1 ] / [ 0 ] ( T s ) = s f [ h − 1 ] / [ 0 ] (10c) \theta^{[h-1]}(T_s) = \theta^{[h-1]}_f, \quad s^{[h-1]/[0]}(T_s) = s^{[h-1]/[0]}_f \tag{10c} θ [ h − 1 ] ( T s ) = θ f [ h − 1 ] , s [ h − 1 ] / [ 0 ] ( T s ) = s f [ h − 1 ] / [ 0 ] ( 10c ) 类比在笛卡尔系规划时,我们指定的终止条件如终点的位置,速度,加速度,曲率等。这里用的是角度,角速度,角加速度,以及弧长,纵向速度,纵向加速度。
θ [ h − 1 ] \theta^{[h-1]} θ [ h − 1 ] θ \theta θ h − 1 h\!-\!1 h − 1 s [ h − 1 ] / [ 0 ] s^{[h-1]/[0]} s [ h − 1 ] / [ 0 ] h − 1 h\!-\!1 h − 1 含义:最终角度及其导数被固定;s s s s ( T s ) s(T_s) s ( T s )
(3) 最终位置:
x ~ f = x f , y ~ f = y f (10d) \tilde{x}_f = x_f, \quad \tilde{y}_f = y_f \tag{10d} x ~ f = x f , y ~ f = y f ( 10d )
( x ~ f , y ~ f ) (\tilde{x}_f,\tilde{y}_f) ( x ~ f , y ~ f ) θ , s \theta,s θ , s ( x f , y f ) (x_f,y_f) ( x f , y f ) 含义:轨迹的积分终点要落在目标点(后文(22)–(25)用增广拉格朗日迭代逼近)。
(4) 分段连续性:
σ i [ h − 1 ] ( T i ) = σ i + 1 [ h − 1 ] ( 0 ) (10e) \sigma^{[h-1]}_i(T_i) = \sigma^{[h-1]}_{i+1}(0) \tag{10e} σ i [ h − 1 ] ( T i ) = σ i + 1 [ h − 1 ] ( 0 ) ( 10e ) 整条轨迹被划分为 M M M ( 2 h − 1 ) (2h-1) ( 2 h − 1 )
要求相邻段在 0~h − 1 h\!-\!1 h − 1
(5) 时间:
T s = ∑ i = 1 M T i , T i > 0 (10f) T_s = \sum_{i=1}^M T_i, \quad T_i > 0 \tag{10f} T s = i = 1 ∑ M T i , T i > 0 ( 10f ) 轨迹执行时间许越小越好,因此这里把时间总和也作为代价。
(6) 约束集合:
C d ( σ ( t ) , … , σ ( h − 1 ) ( t ) ) ≤ 0 , d ∈ D , t ∈ [ 0 , T s ] (10g) C_d(\sigma(t), \dots, \sigma^{(h-1)}(t)) \leq 0, \quad d \in D, \; t \in [0,T_s] \tag{10g} C d ( σ ( t ) , … , σ ( h − 1 ) ( t )) ≤ 0 , d ∈ D , t ∈ [ 0 , T s ] ( 10g )
C d ( ⋅ ) C_d(\cdot) C d ( ⋅ )
(7) 采用ΣMINCO轨迹类来表示轨迹
为了解决该优化问题,我们采用 ΣMINCO [25] 轨迹类 来表示轨迹,并将优化变量进行变换。通过 ΣMINCO,可以把多项式系数 c c c
K ( T ) c = [ σ 0 [ h − 1 ] , σ 1 ′ , 0 , … , σ M − 1 , 0 ′ , σ f [ h − 1 ] ] T (11) K(T)c = [\sigma^{[h-1]}_0, \;\sigma'_1,0,\dots,\sigma'_{M-1,0}, \;\sigma^{[h-1]}_f]^T \tag{11} K ( T ) c = [ σ 0 [ h − 1 ] , σ 1 ′ , 0 , … , σ M − 1 , 0 ′ , σ f [ h − 1 ] ] T ( 11 )
c c c K ( T ) ∈ R 2 M h × 2 M h K(T)\in\mathbb{R}^{2Mh\times 2Mh} K ( T ) ∈ R 2 M h × 2 M h T T T σ i , 0 ′ \sigma'_{i,0} σ i , 0 ′ i i i 0 0 0
然而,目标终点一般是用笛卡尔坐标 ( x f , y f ) (x_f,y_f) ( x f , y f ) s f s_f s f σ f [ h − 1 ] \sigma^{[h-1]}_f σ f [ h − 1 ] s f s_f s f J J J s f s_f s f ∂ J ∂ c \frac{\partial J}{\partial c} ∂ c ∂ J
∂ J ∂ s f = K − T ∂ J ∂ c e ( 2 M − 1 ) h + 1 (12) \frac{\partial J}{\partial s_f} = K^{-T} \frac{\partial J}{\partial c} \, e_{(2M-1)h+1} \tag{12} ∂ s f ∂ J = K − T ∂ c ∂ J e ( 2 M − 1 ) h + 1 ( 12 ) 其中 e i e_i e i I 2 M h I_{2Mh} I 2 M h i i i h = 3 h=3 h = 3
B. 不等式约束与梯度传播
对于目标函数 (10a),其梯度可以直接计算。T i T_i T i T i ∈ R + T_i \in \mathbb{R}^+ T i ∈ R + τ i ∈ R \tau_i \in \mathbb{R} τ i ∈ R
τ i = { 2 T i − 1 − 1 , T i > 1 1 − 2 T i − 1 , T i ≤ 1 (13) \tau_i =
\begin{cases}
\sqrt{2T_i-1} - 1, & T_i > 1 \\
1 - \tfrac{2}{T_i} - 1, & T_i \leq 1
\end{cases} \tag{13} τ i = { 2 T i − 1 − 1 , 1 − T i 2 − 1 , T i > 1 T i ≤ 1 ( 13 ) 对于不等式约束 (10g),我们采用惩罚方法,结合一阶松弛函数 L 1 ( ⋅ ) L_1(\cdot) L 1 ( ⋅ )
C d i , j ( c , T ) = C d ( c i T β ( j n T i ) , … , c i T β ( h − 1 ) ( j n T i ) , x i , j , y i , j ) C_{d}^{i,j}(c,T) = C_d(c_i^T \beta(\tfrac{j}{n}T_i),\dots, c_i^T \beta^{(h-1)}(\tfrac{j}{n}T_i), x_{i,j}, y_{i,j}) C d i , j ( c , T ) = C d ( c i T β ( n j T i ) , … , c i T β ( h − 1 ) ( n j T i ) , x i , j , y i , j )
C d i , j ( c , T ) C_d^{i,j}(c,T) C d i , j ( c , T ) i i i j j j c i c_i c i i i i β ( ⋅ ) \beta(\cdot) β ( ⋅ ) β ( h − 1 ) \beta^{(h-1)} β ( h − 1 ) x i , j , y i , j x_{i,j}, y_{i,j} x i , j , y i , j
罚项构造:
I d ( c , T ) = ς d ∑ i = 1 M ∑ j = 0 n T i n ν j L 1 ( C d i , j ( c , T ) ) (14) I_d(c,T) = \varsigma_d \sum_{i=1}^M \sum_{j=0}^n \frac{T_i}{n} \nu_j L_1(C_d^{i,j}(c,T)) \tag{14} I d ( c , T ) = ς d i = 1 ∑ M j = 0 ∑ n n T i ν j L 1 ( C d i , j ( c , T )) ( 14 )
ζ d \zeta_d ζ d d d d ( ν 0 , … , ν n ) = ( 0.5 , 1 , … , 1 , 0.5 ) (\nu_0, \dots, \nu_n) = (0.5, 1, \dots, 1, 0.5) ( ν 0 , … , ν n ) = ( 0.5 , 1 , … , 1 , 0.5 ) L 1 ( ⋅ ) L_1(\cdot) L 1 ( ⋅ )
当 C d ≤ 0 C_d \le 0 C d ≤ 0 L 1 ( C d ) ≈ 0 L_1(C_d) \approx 0 L 1 ( C d ) ≈ 0
当 C d > 0 C_d > 0 C d > 0 L 1 ( C d ) > 0 L_1(C_d) > 0 L 1 ( C d ) > 0
I d ( c , T ) I_d(c,T) I d ( c , T ) d d d
其中,ς d \varsigma_d ς d d d d ( ν 0 , … , ν n ) = ( 0.5 , 1 , … , 1 , 0.5 ) (\nu_0,\dots,\nu_n) = (0.5,1,\dots,1,0.5) ( ν 0 , … , ν n ) = ( 0.5 , 1 , … , 1 , 0.5 ) n n n
于是,优化问题可以重新写为:
min w σ ′ , τ , s f J s = J 0 ( c ( w σ ′ , τ , s f ) , T ( τ ) ) + I d ( c ( w σ ′ , τ , s f ) , T ( τ ) ) (15) \min_{w\sigma', \tau, s_f} J_s = J_0(c(w\sigma',\tau,s_f), T(\tau)) + I_d(c(w\sigma',\tau,s_f), T(\tau)) \tag{15} w σ ′ , τ , s f min J s = J 0 ( c ( w σ ′ , τ , s f ) , T ( τ )) + I d ( c ( w σ ′ , τ , s f ) , T ( τ )) ( 15 )
J 0 J_0 J 0 I d I_d I d 优化变量:
w σ ′ w_{\sigma'} w σ ′ τ \tau τ s f s_f s f
梯度为什么重要?
公式(15)是一个 无约束非线性优化问题,本质上靠数值迭代解。在本文中:
等式约束(终点、段间连续性):用 PHR-ALM 增广拉格朗日,逐步修正,确保严格满足。
不等式约束(避障、速度等):用 罚函数法,把它们变成目标函数的附加项。
处理完之后,优化问题就变成了一个 光滑的无约束优化问题。最后的无约束优化问题是用 L-BFGS(Limited-memory BFGS)来解的。因为 L-BFGS 是一个 梯度型方法,所以我们要准确计算相应的梯度。涉及到的梯度如下表:
梯度类型 对应公式 数学对象 物理意义 约束对系数 c c c (16) ∂ C d ∂ c \frac{\partial C_d}{\partial c} ∂ c ∂ C d 如果改变多项式系数(轨迹形状),约束值(如避障距离)会怎样变化;告诉优化器应如何调整轨迹形状来满足约束。 约束对时间 T T T (17) ∂ C d ∂ T \frac{\partial C_d}{\partial T} ∂ T ∂ C d 如果某段轨迹的时间长短调整,约束会怎样变化;例如加快/减慢速度是否有助于避障。 罚项对系数 c c c (18) ∂ I d ∂ c \frac{\partial I_d}{\partial c} ∂ c ∂ I d 综合所有采样点,整体衡量轨迹形状改变对约束罚分的影响。 罚项对时间 T T T (19) ∂ I d ∂ T \frac{\partial I_d}{\partial T} ∂ T ∂ I d 综合所有采样点,衡量时间分配改变对约束罚分的影响。 积分位置对系数的梯度 (20) ∂ x i , j ∂ c m \frac{\partial x_{i,j}}{\partial c_m} ∂ c m ∂ x i , j 因为 x , y x,y x , y 积分位置对时间的梯度 (21) ∂ x i , j ∂ T m \frac{\partial x_{i,j}}{\partial T_m} ∂ T m ∂ x i , j 早期段的时间分配改变,会影响后续点位置;描述时间变化如何影响整条轨迹的位置和约束。
下表开始讨论梯度的计算公式。
(1) 约束对系数 c c c
∂ C d ∂ c = ∑ h = 0 h − 1 β ( h ) ( ∂ C d ∂ σ ( h ) ) T + ∂ x ∂ c ∂ C d ∂ x + ∂ y ∂ c ∂ C d ∂ y (16) \frac{\partial C_d}{\partial c}
= \sum_{h=0}^{h-1} \beta^{(h)}\left(\frac{\partial C_d}{\partial \sigma^{(h)}}\right)^T
+ \frac{\partial x}{\partial c}\frac{\partial C_d}{\partial x}
+ \frac{\partial y}{\partial c}\frac{\partial C_d}{\partial y}
\tag{16} ∂ c ∂ C d = h = 0 ∑ h − 1 β ( h ) ( ∂ σ ( h ) ∂ C d ) T + ∂ c ∂ x ∂ x ∂ C d + ∂ c ∂ y ∂ y ∂ C d ( 16 )
C d C_d C d c c c σ ( h ) \sigma^{(h)} σ ( h ) h h h x , y x,y x , y
通过链式法则,把约束对 c c c
对状态的直接依赖;
对 x x x
对 y y y
(2) 约束对时间 T T T
∂ C d ∂ T = ∑ h = 0 h − 1 ∂ σ ( h ) ∂ T ∂ C d ∂ σ ( h ) + ∂ x ∂ T ∂ C d ∂ x + ∂ y ∂ T ∂ C d ∂ y (17) \frac{\partial C_d}{\partial T}
= \sum_{h=0}^{h-1} \frac{\partial \sigma^{(h)}}{\partial T}\frac{\partial C_d}{\partial \sigma^{(h)}}
+ \frac{\partial x}{\partial T}\frac{\partial C_d}{\partial x}
+ \frac{\partial y}{\partial T}\frac{\partial C_d}{\partial y}
\tag{17} ∂ T ∂ C d = h = 0 ∑ h − 1 ∂ T ∂ σ ( h ) ∂ σ ( h ) ∂ C d + ∂ T ∂ x ∂ x ∂ C d + ∂ T ∂ y ∂ y ∂ C d ( 17 ) 类似 (16),只不过这里是约束对时间 T T T T T T
(3) 罚项 I d I_d I d c c c
∂ I d ∂ c = ζ d ∑ i = 1 M ∑ j = 0 n T i n ν j ∂ C d ∂ c ∂ L 1 ( C d ) ∂ C d (18) \frac{\partial I_d}{\partial c}
= \zeta_d \sum_{i=1}^M \sum_{j=0}^n \frac{T_i}{n}\,\nu_j
\frac{\partial C_d}{\partial c}
\frac{\partial L_1(C_d)}{\partial C_d}
\tag{18} ∂ c ∂ I d = ζ d i = 1 ∑ M j = 0 ∑ n n T i ν j ∂ c ∂ C d ∂ C d ∂ L 1 ( C d ) ( 18 )
ζ d \zeta_d ζ d ν j \nu_j ν j ( 0.5 , 1 , … , 1 , 0.5 ) (0.5, 1, \dots, 1, 0.5) ( 0.5 , 1 , … , 1 , 0.5 ) L 1 ( ⋅ ) L_1(\cdot) L 1 ( ⋅ )
罚项对 c c c
(4) 罚项 I d I_d I d T T T
∂ I d ∂ T = ζ d ∑ i = 1 M ∑ j = 0 n ν j ( 1 n L 1 ( C d ) e i + T i n ∂ C d ∂ T ∂ L 1 ( C d ) ∂ C d ) (19) \frac{\partial I_d}{\partial T}
= \zeta_d \sum_{i=1}^M \sum_{j=0}^n \nu_j
\left(\frac{1}{n} L_1(C_d) e_i
+ \frac{T_i}{n}\frac{\partial C_d}{\partial T}
\frac{\partial L_1(C_d)}{\partial C_d}\right)
\tag{19} ∂ T ∂ I d = ζ d i = 1 ∑ M j = 0 ∑ n ν j ( n 1 L 1 ( C d ) e i + n T i ∂ T ∂ C d ∂ C d ∂ L 1 ( C d ) ) ( 19 )
e i e_i e i T i T_i T i
罚项对 T T T
直接来自 L 1 ( C d ) L_1(C_d) L 1 ( C d )
来自 C d C_d C d T T T
(5) x i , j x_{i,j} x i , j c c c
∂ x i , j ∂ c m ∂ C d ∂ x i , j = g i , j x ( T m 6 n ∑ k = 1 n ∂ Γ m , k ∂ c m ) , m ∈ [ 1 , i − 1 ] (20) \frac{\partial x_{i,j}}{\partial c_m}\frac{\partial C_d}{\partial x_{i,j}}
= g^x_{i,j}\left(\frac{T_m}{6n}\sum_{k=1}^n
\frac{\partial \Gamma_{m,k}}{\partial c_m}\right),
\quad m \in [1,i-1]
\tag{20} ∂ c m ∂ x i , j ∂ x i , j ∂ C d = g i , j x ( 6 n T m k = 1 ∑ n ∂ c m ∂ Γ m , k ) , m ∈ [ 1 , i − 1 ] ( 20 )
x i , j x_{i,j} x i , j i i i j j j x x x c m c_m c m m m m Γ m , k = x ^ k , 0 + 4 x ^ k , 1 + x ^ k , 2 \Gamma_{m,k} = \hat{x}^{k,0} + 4\hat{x}^{k,1} + \hat{x}^{k,2} Γ m , k = x ^ k , 0 + 4 x ^ k , 1 + x ^ k , 2 g i , j x g^x_{i,j} g i , j x x i , j x_{i,j} x i , j
x i , j x_{i,j} x i , j
(6) x i , j x_{i,j} x i , j T T T
∂ x i , j ∂ T m ∂ C d ∂ x i , j = g i , j x ∑ k = 1 n ( Γ m , k 6 n + T m 6 n ∂ Γ m , k ∂ T m ) , m ∈ [ 1 , i − 1 ] (21) \frac{\partial x_{i,j}}{\partial T_m}\frac{\partial C_d}{\partial x_{i,j}}
= g^x_{i,j}\sum_{k=1}^n
\left(\frac{\Gamma_{m,k}}{6n}
+ \frac{T_m}{6n}\frac{\partial \Gamma_{m,k}}{\partial T_m}\right),
\quad m \in [1,i-1]
\tag{21} ∂ T m ∂ x i , j ∂ x i , j ∂ C d = g i , j x k = 1 ∑ n ( 6 n Γ m , k + 6 n T m ∂ T m ∂ Γ m , k ) , m ∈ [ 1 , i − 1 ] ( 21 ) 与 (20) 类似,不过这里是 x i , j x_{i,j} x i , j x i , j x_{i,j} x i , j
C. 终点位置约束
与基于微分平坦性的轨迹不同,MS 轨迹的最终位置是通过积分近似计算得到的,因此可能与期望目标 ( x f , y f ) (x_f,y_f) ( x f , y f )
以 x x x
C f x ( c , T ) = x ~ f ( c , T ) − x f (22) C_f^x(c,T) = \tilde{x}_f(c,T) - x_f \tag{22} C f x ( c , T ) = x ~ f ( c , T ) − x f ( 22 ) 通常允许存在最大误差 e max e_{\max} e m a x
因此,作者采用 Powell-Hestenes-Rockafellar 增广拉格朗日方法 (PHR-ALM) 来迭代减少误差。
J ρ ( w σ ′ , τ , s f , λ ) : = J s ′ + ∑ ι ∈ { x , y } ρ 2 ∥ C f ι ( c ( w σ ′ , τ , s f ) , T ( τ ) ) + λ ι ρ ∥ 2 (23) J_\rho(w\sigma',\tau,s_f,\lambda) := J'_s +
\sum_{\iota \in \{x,y\}} \frac{\rho}{2} \| C_f^\iota(c(w\sigma',\tau,sf), T(\tau)) + \tfrac{\lambda_\iota}{\rho} \|^2 \tag{23} J ρ ( w σ ′ , τ , s f , λ ) := J s ′ + ι ∈ { x , y } ∑ 2 ρ ∥ C f ι ( c ( w σ ′ , τ , s f ) , T ( τ )) + ρ λ ι ∥ 2 ( 23 ) 其中,λ \lambda λ ρ > 0 \rho>0 ρ > 0
更新方式如下:
{ ( w σ ′ k + 1 , τ k + 1 , s f k + 1 ) = arg min J ρ ( w σ ′ , τ , s f , λ k ) λ ι k + 1 = λ ι k + ρ k C f ι , ι ∈ { x , y } ρ k + 1 = min [ ( 1 + ϱ ) ρ k , ρ max ] (24) \begin{cases}
(w\sigma'^{k+1}, \tau^{k+1}, s_f^{k+1}) = \arg\min J_\rho(w\sigma',\tau,s_f,\lambda^k) \\
\lambda_\iota^{k+1} = \lambda_\iota^k + \rho^k C_f^\iota, \quad \iota \in \{x,y\} \\
\rho^{k+1} = \min[(1+\varrho)\rho^k, \rho_{\max}]
\end{cases} \tag{24} ⎩ ⎨ ⎧ ( w σ ′ k + 1 , τ k + 1 , s f k + 1 ) = arg min J ρ ( w σ ′ , τ , s f , λ k ) λ ι k + 1 = λ ι k + ρ k C f ι , ι ∈ { x , y } ρ k + 1 = min [( 1 + ϱ ) ρ k , ρ m a x ] ( 24 ) 其中 ϱ > 0 \varrho>0 ϱ > 0 ρ k \rho^k ρ k ρ max \rho_{\max} ρ m a x
( x ~ f − x f ) 2 + ( y ~ f − y f ) 2 < e max (25) (\tilde{x}_f - x_f)^2 + (\tilde{y}_f - y_f)^2 < e_{\max} \tag{25} ( x ~ f − x f ) 2 + ( y ~ f − y f ) 2 < e m a x ( 25 ) 即保证最终位置误差在容许范围内。
公式 (23) 是本文中最终的轨迹优化目标函数,它采用 Powell-Hestenes-Rockafellar 增广拉格朗日方法 (PHR-ALM) 来处理轨迹的最终位置约束。
该公式将需要精确满足的等式约束(最终位置)与所有通过惩罚函数方法处理的不等式约束统一在一个迭代可解的增广目标函数中。
项 含义 (中文) 含义 (英文/数学) 作用与来源 J ρ ( ⋅ ) \mathbf{J}_\rho(\cdot) J ρ ( ⋅ ) 增广拉格朗日目标函数 Augmented Lagrangian Objective Function 这是 ALM 迭代优化中的最小化目标函数。优化器(如 L-BFGS)在每次迭代中求解最小化该函数的问题。 w σ ′ , τ , s f w_{\sigma}', \tau, s_f w σ ′ , τ , s f 优化变量 Optimization Variables 轨迹优化的变量集:w σ ′ w_{\sigma}' w σ ′ τ \tau τ T i T_i T i s f s_f s f λ \lambda λ 对偶变量/拉格朗日乘子 Dual Variable / Lagrange Multiplier 用于最终位置等式约束的对偶变量。在 ALM 迭代的外层循环中根据约束违反程度进行更新 (Eq. 24)。 J s ′ \mathbf{J}' _s J s ′ 基础无约束目标函数 Unconstrained Optimization Problem (J s J_s J s 这是排除了最终位置约束,并将所有不等式约束(集合 D D D J s ′ \mathbf{J}' _s J s ′ J 0 J_0 J 0 ∑ I d \sum I_d ∑ I d ∑ ι = x , y \sum_{\iota=x,y} ∑ ι = x , y 求和项 Summation 对笛卡尔坐标系的 x x x y y y ρ 2 ∥ ⋅ ∥ 2 \frac{\rho}{2} \|\cdot\|^2 2 ρ ∥ ⋅ ∥ 2 增广项的系数 C f ι ( ⋅ ) C_{f\iota}(\cdot) C f ι ( ⋅ ) 最终位置约束函数 Final Position Constraint Function 表示最终位置的等式约束 [30d, 41]。具体地,它定义了轨迹的最终近似位置 (x ~ f \tilde{x}_f x ~ f y ~ f \tilde{y}_f y ~ f x f x_f x f y f y_f y f C f ι = ι ~ f − ι f ( ι = x , y ) C_{f\iota} = \tilde{\iota}_f - \iota_f \quad (\iota=x, y) \quad \text{} C f ι = ι ~ f − ι f ( ι = x , y ) λ ι ρ \frac{\lambda_{\iota}}{\rho} ρ λ ι 对偶变量修正项 Dual Variable Correction Term 这是 ALM 区别于简单二次惩罚的关键部分,用于修正惩罚项的中心,以提高收敛速度和准确性。 ∥ C f ι ( ⋅ ) + λ ι ρ ∥ 2 \left\|\mathbf{C}_{f\iota}(\cdot) + \frac{\lambda_{\iota}}{\rho} \right\|^2 C f ι ( ⋅ ) + ρ λ ι 2 增广拉格朗日项
统一约束的机制
公式 (23) 体现了优化框架对不同类型约束的分层处理策略:
内层惩罚 (J s ′ J'_s J s ′ I d I_d I d
外层增广 (J ρ J_\rho J ρ x f , y f x_f, y_f x f , y f w σ ′ , τ , s f w_{\sigma}', \tau, s_f w σ ′ , τ , s f J s ′ J'_s J s ′
附件:问题列表
Q1.为什么要用y I l , y I r y_{Il},y_{Ir} y I l , y I r
这里对于标准的二轮差分底盘,没有横向滑移,y I l − y I r = d w b y_{Il}-y_{Ir}=d_{wb} y I l − y I r = d w b y I l − y I r ≠ d w b y_{Il}-y_{Ir} \neq d_{wb} y I l − y I r = d w b y I l , y I r y_{Il}, y_{Ir} y I l , y I r
Q2. iLQR / MPC 的线性化 vs Simpson 数值积分
(1) iLQR 的线性化
对象:非线性动力学 x t + 1 = f ( x t , u t ) x_{t+1} = f(x_t,u_t) x t + 1 = f ( x t , u t )
方法:在参考轨迹附近做泰勒展开,一阶近似
δ x t + 1 ≈ A t δ x t + B t δ u t \delta x_{t+1} \approx A_t \delta x_t + B_t \delta u_t δ x t + 1 ≈ A t δ x t + B t δ u t
目的:把非线性 OCP 转化为 LQR 子问题,通过迭代求得全局近似最优解。
特点:迭代优化,全局一致性,计算量大。
(2) MPC 的逐步线性化
对象:非线性动力学
方法:在每个滚动时域的当前状态处线性化,只解一次优化问题。
目的:得到实时可用的控制输入,保证 MPC 能在强约束下运行。
特点:不迭代,每步线性化一次,实时性好但最优性弱。
(3) Simpson 数值积分
对象:积分算子,例如轨迹坐标转换
x ( t ) = ∫ 0 t [ s ˙ ( τ ) cos θ ( τ ) − v y ( τ ) sin θ ( τ ) ] d τ x(t)=\int_0^t [\dot{s}(\tau)\cos\theta(\tau)-v_y(\tau)\sin\theta(\tau)] d\tau x ( t ) = ∫ 0 t [ s ˙ ( τ ) cos θ ( τ ) − v y ( τ ) sin θ ( τ )] d τ
方法:用 Simpson 公式近似积分
∫ a b f ( ξ ) d ξ ≈ b − a 6 [ f ( a ) + 4 f ( a + b 2 ) + f ( b ) ] \int_a^b f(\xi)d\xi \approx \tfrac{b-a}{6}\,[f(a)+4f(\tfrac{a+b}{2})+f(b)] ∫ a b f ( ξ ) d ξ ≈ 6 b − a [ f ( a ) + 4 f ( 2 a + b ) + f ( b )]
目的:在轨迹优化中高效、可微地计算积分值。
特点:数值计算近似,不是模型近似;误差阶次 O ( h 4 ) O(h^4) O ( h 4 )
(4) 总结
iLQR/MPC 的线性化 → 针对动力学模型,是“模型近似”,核心目的是 让优化问题可解。
Simpson 积分 → 针对积分运算,是“计算近似”,核心目的是 让积分算得快而准。
方法 面向对象 技术手段 目的 iLQR 线性化 非线性动力学 泰勒展开 (一阶/二阶) 降低优化难度,迭代求近似最优解 MPC 线性化 非线性动力学 每步局部线性化 实时优化,快速可行解 Simpson 积分 积分算子 数值近似(插值求积) 高效计算积分,便于轨迹约束
Q3.前进切换到后退的换挡点,需要依赖初始解吗?
这个特性感觉有点厉害了,类似这种换挡的轨迹,不知道需不需要要依赖初始解,如果它能够自动找到最优换挡点,那就太厉害了。
MS 轨迹具有显著优势,它能够避免由于非完整约束动力学所引起的奇异性。这意味着,一条统一的轨迹就可以同时包含前进和后退两种运动,而不需要由前端规划器显式指定。
换挡点是优化的自由度,优化器会在代价函数(安全性、平滑性、能耗等)和约束条件(动力学、障碍物)下,自动决定最优的切换时机和位置。
这个问题的答案需要在代码里进行确认,之后公布。
Q4.轨迹优化中目标函数都有哪些构成
(A) 最终目标:PHR-ALM 形式
J ρ ( w σ ′ , τ , s f , λ ) = J s ′ ⏟ 惩罚基底目标 + ∑ ι ∈ { x , y } ρ 2 ∥ C f ι ( c ( w σ ′ , τ , s f ) , T ( τ ) ) + λ ι ρ ∥ 2 ⏟ ALM 增广:仅用于终点位置等式约束 \boxed{
J_{\rho}\!\left(w_{\sigma'},\,\tau,\,s_f,\,\lambda\right)
=
\underbrace{J'_s}_{\text{惩罚基底目标}}
\;+\;
\underbrace{\sum_{\iota\in\{x,y\}}\frac{\rho}{2}\,\left\|
C_{f\iota}\!\big(c(w_{\sigma'},\tau,s_f),\,T(\tau)\big)+\frac{\lambda_\iota}{\rho}
\right\|^2}_{\text{ALM 增广:仅用于终点位置等式约束}}
} J ρ ( w σ ′ , τ , s f , λ ) = 惩罚基底目标 J s ′ + ALM 增广:仅用于终点位置等式约束 ι ∈ { x , y } ∑ 2 ρ C f ι ( c ( w σ ′ , τ , s f ) , T ( τ ) ) + ρ λ ι 2 (B) 惩罚基底目标 J s ′ J'_s J s ′
J s ′ = J 0 ( c , T ) + ∑ d ∈ D I d ( c , T ) \boxed{
J'_s
=
J_0(c,T)
\;+\;
\sum_{d\in D} I_d(c,T)
} J s ′ = J 0 ( c , T ) + d ∈ D ∑ I d ( c , T ) (C) 平滑度 + 时间正则 J 0 J_0 J 0
J 0 ( c , T ) = ∫ 0 T s σ ( h ) ( t ) ⊤ W σ ( h ) ( t ) d t + ε T T s , T s = ∑ i = 1 M T i > 0 \boxed{
J_0(c,T)
=
\int_{0}^{T_s}\!\sigma^{(h)}(t)^{\!\top} W \,\sigma^{(h)}(t)\,dt
\;+\;
\varepsilon_T\,T_s,
\quad
T_s=\sum_{i=1}^{M}T_i>0
} J 0 ( c , T ) = ∫ 0 T s σ ( h ) ( t ) ⊤ W σ ( h ) ( t ) d t + ε T T s , T s = i = 1 ∑ M T i > 0 (D) 不等式约束惩罚项 I d I_d I d
I d ( c , T ) = ς d ∑ i = 1 M ∑ j = 0 n T i n ν j L 1 ( C d i , j ( c , T ) ) ( ν 0 = ν n = 1 2 , ν 1.. n − 1 = 1 ) \boxed{
I_d(c,T)
=
\varsigma_d
\sum_{i=1}^{M}\sum_{j=0}^{n}
\frac{T_i}{n}\,\nu_j\,
L_1\!\Big(C^{\,i,j}_d\!\big(c,T\big)\Big)
}
\qquad
(\nu_0=\nu_n=\tfrac12,\ \nu_{1..n-1}=1) I d ( c , T ) = ς d i = 1 ∑ M j = 0 ∑ n n T i ν j L 1 ( C d i , j ( c , T ) ) ( ν 0 = ν n = 2 1 , ν 1.. n − 1 = 1 ) 采样点约束函数:
C d i , j ( c , T ) = C d ( σ ( 0.. h − 1 ) ( j n T i ) , x i , j , y i , j ) C^{\,i,j}_d(c,T)
=
C_d\!\left(
\sigma^{(0..h-1)}\!\Big(\tfrac{j}{n}T_i\Big),\;
x_{i,j},\;y_{i,j}
\right) C d i , j ( c , T ) = C d ( σ ( 0.. h − 1 ) ( n j T i ) , x i , j , y i , j ) (E) 终点位置残差 C f ι C_{f\iota} C f ι
C f x ( c , T ) = x ~ f ( c , T ) − x f , C f y ( c , T ) = y ~ f ( c , T ) − y f \boxed{
C_{fx}(c,T)=\tilde{x}_f(c,T)-x_f,
\qquad
C_{fy}(c,T)=\tilde{y}_f(c,T)-y_f
} C f x ( c , T ) = x ~ f ( c , T ) − x f , C f y ( c , T ) = y ~ f ( c , T ) − y f (F) 末端位置积分(辛普森法)
x ~ f = ∑ i = 1 M x i ( c i , T i ) + x 0 , x i ( c i , T i ) = T i 6 n ∑ j = 1 n ( x ^ i j , 0 + 4 x ^ i j , 1 + x ^ i j , 2 ) \tilde{x}_f
=
\sum_{i=1}^{M} x_i(c_i,T_i) + x_0,
\quad
x_i(c_i,T_i)
=
\frac{T_i}{6n}
\sum_{j=1}^{n}
\Big(
\hat{x}^{\,j,0}_i + 4\hat{x}^{\,j,1}_i + \hat{x}^{\,j,2}_i
\Big) x ~ f = i = 1 ∑ M x i ( c i , T i ) + x 0 , x i ( c i , T i ) = 6 n T i j = 1 ∑ n ( x ^ i j , 0 + 4 x ^ i j , 1 + x ^ i j , 2 ) y ~ f = ∑ i = 1 M y i ( c i , T i ) + y 0 , y i ( c i , T i ) = T i 6 n ∑ j = 1 n ( y ^ i j , 0 + 4 y ^ i j , 1 + y ^ i j , 2 ) \tilde{y}_f
=
\sum_{i=1}^{M} y_i(c_i,T_i) + y_0,
\quad
y_i(c_i,T_i)
=
\frac{T_i}{6n}
\sum_{j=1}^{n}
\Big(
\hat{y}^{\,j,0}_i + 4\hat{y}^{\,j,1}_i + \hat{y}^{\,j,2}_i
\Big) y ~ f = i = 1 ∑ M y i ( c i , T i ) + y 0 , y i ( c i , T i ) = 6 n T i j = 1 ∑ n ( y ^ i j , 0 + 4 y ^ i j , 1 + y ^ i j , 2 ) 被积函数:
x ^ i j , l = s ˙ ( T i j , l ) cos θ ( T i j , l ) + x I v θ ˙ ( T i j , l ) sin θ ( T i j , l ) \hat{x}^{\,j,l}_i
=
\dot{s}\!\big(T^{j,l}_i\big)\cos\theta\!\big(T^{j,l}_i\big)
+
x_{Iv}\,\dot{\theta}\!\big(T^{j,l}_i\big)\sin\theta\!\big(T^{j,l}_i\big) x ^ i j , l = s ˙ ( T i j , l ) cos θ ( T i j , l ) + x I v θ ˙ ( T i j , l ) sin θ ( T i j , l ) y ^ i j , l = s ˙ ( T i j , l ) sin θ ( T i j , l ) − x I v θ ˙ ( T i j , l ) cos θ ( T i j , l ) \hat{y}^{\,j,l}_i
=
\dot{s}\!\big(T^{j,l}_i\big)\sin\theta\!\big(T^{j,l}_i\big)
-
x_{Iv}\,\dot{\theta}\!\big(T^{j,l}_i\big)\cos\theta\!\big(T^{j,l}_i\big) y ^ i j , l = s ˙ ( T i j , l ) sin θ ( T i j , l ) − x I v θ ˙ ( T i j , l ) cos θ ( T i j , l ) (G) 多项式系数 (c) 的线性关系
K ( T ) c = [ σ 0 [ h − 1 ] , σ 1 , 0 ′ , … , σ M − 1 , 0 ′ , σ f [ h − 1 ] ] ⊤ \boxed{
K(T)\,c
=
\big[
\ \sigma^{[h-1]}_0,\ \sigma'_{1,0},\dots,\sigma'_{M-1,0},\ \sigma^{[h-1]}_f\
\big]^{\!\top}
} K ( T ) c = [ σ 0 [ h − 1 ] , σ 1 , 0 ′ , … , σ M − 1 , 0 ′ , σ f [ h − 1 ] ] ⊤ 因此 c = c ( w σ ′ , T , s f ) c=c(w_{\sigma'},\,T,\,s_f) c = c ( w σ ′ , T , s f )
(H) 时间正性(平滑双射)
τ i = { 2 T i − 1 − 1 , T i > 1 1 − 2 T i − 1 , T i ≤ 1 ⟺ T i = T i ( τ i ) > 0 \tau_i =
\begin{cases}
\sqrt{2T_i}-1-1, & T_i>1 \\[2pt]
1-\sqrt{\dfrac{2}{T_i}-1}, & T_i\le 1
\end{cases}
\quad\Longleftrightarrow\quad
T_i=T_i(\tau_i)>0 τ i = ⎩ ⎨ ⎧ 2 T i − 1 − 1 , 1 − T i 2 − 1 , T i > 1 T i ≤ 1 ⟺ T i = T i ( τ i ) > 0 (I) 末端弧长 s f s_f s f
∂ J ∂ s f = K ( T ) − ⊤ ∂ J ∂ c e ( 2 M − 1 ) h + 1 \frac{\partial J}{\partial s_f}
=
K(T)^{-\top}\,
\frac{\partial J}{\partial c}\,
e_{(2M-1)h+1} ∂ s f ∂ J = K ( T ) − ⊤ ∂ c ∂ J e ( 2 M − 1 ) h + 1 (J) 总览:所有子项回收至最终式
J ρ ( w σ ′ , τ , s f , λ ) = ( ∫ 0 ∑ i T i ( τ ) σ ( h ) ( t ) ⊤ W σ ( h ) ( t ) d t + ε T ∑ i T i ( τ ) ⏟ J 0 平滑度+时间代价 + ∑ d ς d ∑ i = 1 M ∑ j = 0 n T i ( τ ) n ν j L 1 ( C d i , j ( c ( w σ ′ , τ , s f ) , T ( τ ) ) ) ⏟ ∑ I d 不等式约束的惩罚项 ) ⏟ J s ′ 惩罚基底目标 + ∑ ι ∈ { x , y } ρ 2 ∥ p ~ f , ι ( c ( w σ ′ , τ , s f ) , T ( τ ) ) − p f , ι ⏟ C f ι 终点位置残差 + λ ι ρ ∥ ALM 增广项 2 \begin{aligned}
J_{\rho}(w_{\sigma'},\tau,s_f,\lambda)
&=
\underbrace{\Big(
\underbrace{\int_{0}^{\sum_i T_i(\tau)}\!\!\sigma^{(h)}(t)^{\!\top}
W\sigma^{(h)}(t)\,dt+\varepsilon_T\sum_i T_i(\tau)}_{J_0 \;\;\;\;\text{平滑度+时间代价}}
\;+\;
\underbrace{\sum_{d}\varsigma_d\sum_{i=1}^{M}\sum_{j=0}^{n}
\tfrac{T_i(\tau)}{n}\nu_j\,L_1\big(C^{\,i,j}_d(c(w_{\sigma'},\tau,s_f),T(\tau))\big)}_{\sum I_d \;\;\;\;\text{不等式约束的惩罚项}}
\Big)}_{J'_s \;\;\;\;\text{惩罚基底目标}}
\\
&\quad+\;
\sum_{\iota\in\{x,y\}}
\frac{\rho}{2}\,
\left\|
\underbrace{\tilde{p}_{f,\iota}(c(w_{\sigma'},\tau,s_f),T(\tau)) - p_{f,\iota}}_{C_{f\iota}\;\;\;\;\text{终点位置残差}}
+\frac{\lambda_\iota}{\rho}
\right\|^2_{\;\;\;\;\text{ALM 增广项}}
\end{aligned} J ρ ( w σ ′ , τ , s f , λ ) = J s ′ 惩罚基底目标 ( J 0 平滑度 + 时间代价 ∫ 0 ∑ i T i ( τ ) σ ( h ) ( t ) ⊤ W σ ( h ) ( t ) d t + ε T i ∑ T i ( τ ) + ∑ I d 不等式约束的惩罚项 d ∑ ς d i = 1 ∑ M j = 0 ∑ n n T i ( τ ) ν j L 1 ( C d i , j ( c ( w σ ′ , τ , s f ) , T ( τ )) ) ) + ι ∈ { x , y } ∑ 2 ρ C f ι 终点位置残差 p ~ f , ι ( c ( w σ ′ , τ , s f ) , T ( τ )) − p f , ι + ρ λ ι ALM 增广项 2 (1) 第一大块:J s ′ J'_s J s ′
J s ′ = J 0 + ∑ d I d J'_s = J_0 + \sum_d I_d J s ′ = J 0 + d ∑ I d
J 0 J_0 J 0 ∑ I d \sum I_d ∑ I d 因此,J s ′ J'_s J s ′
(2) 第二大块:ALM 增广项
∑ ι ∈ { x , y } ρ 2 ∥ C f ι ( c , T ) + λ ι ρ ∥ 2 \sum_{\iota \in \{x,y\}} \frac{\rho}{2}
\left\|
C_{f\iota}(c,T) + \frac{\lambda_\iota}{\rho}
\right\|^2 ι ∈ { x , y } ∑ 2 ρ C f ι ( c , T ) + ρ λ ι 2
C f ι C_{f\iota} C f ι ( x ~ f , y ~ f ) (\tilde{x}_f,\tilde{y}_f) ( x ~ f , y ~ f ) ( x f , y f ) (x_f,y_f) ( x f , y f ) λ ι , ρ \lambda_\iota, \rho λ ι , ρ 通过 ALM 增广形式,把“终点位置必须精确到目标点”这一 等式约束 纳入目标函数,保证迭代收敛到高精度。
(3) 最终目标函数总结
J ρ = J 0 + ∑ d I d ⏟ J s ′ 惩罚基底目标 + ∑ ι ∈ { x , y } ρ 2 ∥ C f ι ( c , T ) + λ ι ρ ∥ 2 ⏟ ALM 增广项(终点位置等式约束) J_\rho
=
\underbrace{J_0 + \sum_d I_d}_{J'_s \;\;\; \text{惩罚基底目标}}
+
\underbrace{\sum_{\iota \in \{x,y\}} \frac{\rho}{2}
\left\|
C_{f\iota}(c,T) + \frac{\lambda_\iota}{\rho}
\right\|^2}_{\text{ALM 增广项(终点位置等式约束)}} J ρ = J s ′ 惩罚基底目标 J 0 + d ∑ I d + ALM 增广项(终点位置等式约束) ι ∈ { x , y } ∑ 2 ρ C f ι ( c , T ) + ρ λ ι 2 Q5.ALM 外层更新中J s ′ J'_s J s ′
(1) 最终目标函数
J ρ ( w σ ′ , τ , s f , λ ) = J s ′ + ∑ ι ∈ { x , y } ρ 2 ∥ C f ι ( c , T ) + λ ι ρ ∥ 2 J_\rho(w_{\sigma'}, \tau, s_f, \lambda)
=
J'_s
+
\sum_{\iota \in \{x,y\}}
\frac{\rho}{2}\left\|
C_{f\iota}(c,T) + \frac{\lambda_\iota}{\rho}
\right\|^2 J ρ ( w σ ′ , τ , s f , λ ) = J s ′ + ι ∈ { x , y } ∑ 2 ρ C f ι ( c , T ) + ρ λ ι 2
J s ′ J'_s J s ′ 增广项: 针对终点位置等式约束 C f x , C f y C_{fx}, C_{fy} C f x , C f y
(2) 外层更新规则
固定 ( λ k , ρ k ) (\lambda^k, \rho^k) ( λ k , ρ k )
( w σ ′ k + 1 , τ k + 1 , s f k + 1 ) = arg min J ρ ( ⋅ ; λ k , ρ k ) (w_{\sigma'}^{k+1}, \tau^{k+1}, s_f^{k+1})
= \arg\min J_\rho(\cdot; \lambda^k, \rho^k) ( w σ ′ k + 1 , τ k + 1 , s f k + 1 ) = arg min J ρ ( ⋅ ; λ k , ρ k )
更新拉格朗日乘子
λ ι k + 1 = λ ι k + ρ k C f ι ( c , T ) , ι ∈ { x , y } \lambda^{k+1}_\iota = \lambda^k_\iota + \rho^k \, C_{f\iota}(c,T),
\quad \iota \in \{x,y\} λ ι k + 1 = λ ι k + ρ k C f ι ( c , T ) , ι ∈ { x , y }
更新罚参数
ρ k + 1 = min { ( 1 + ϱ ) ρ k , ρ max } \rho^{k+1} = \min\{(1+\varrho)\rho^k,\ \rho_{\max}\} ρ k + 1 = min {( 1 + ϱ ) ρ k , ρ m a x }
收敛条件
( x ~ f − x f ) 2 + ( y ~ f − y f ) 2 < e max \sqrt{(\tilde{x}_f - x_f)^2 + (\tilde{y}_f - y_f)^2} < e_{\max} ( x ~ f − x f ) 2 + ( y ~ f − y f ) 2 < e m a x
(3) J s ′ J'ₛ J s ′
a) 参与内层最小化
每次优化时,J s ′ J'_s J s ′
它确保轨迹光滑并满足不等式约束。
b) 不参与外层更新
外层更新 ( λ , ρ ) (\lambda, \rho) ( λ , ρ ) C f x , C f y C_{fx}, C_{fy} C f x , C f y
与 J s ′ J'_s J s ′
Q6.为什么避障约束没有作为ALM项,而是单纯用罚函数呢
这个论文里没有提到,暂时不清楚原因。以下是推测的原因。
避障约束之所以没有采用增强拉格朗日方法(Augmented Lagrangian Methods, ALM),而是使用单纯的罚函数,主要是因为这两种方法针对的目标约束类型和所需的精度要求有所不同。
(1) 避障约束的处理方式(罚函数)
在所提出的通用轨迹优化框架中,避障约束(即安全约束)属于一般的不等式约束集合 D D D C s , l C_{s,l} C s , l
定义和目的: 安全约束 C s , l C_{s,l} C s , l χ b , l \chi_{b,l} χ b , l p b , l p_{b,l} p b , l d s d_s d s C s , l ( x , y , θ ) = d s − E ( p b , l ( x , y , θ ) ) C_{s,l}(x, y, \theta) = d_s - E(p_{b,l}(x, y, \theta)) C s , l ( x , y , θ ) = d s − E ( p b , l ( x , y , θ ))
实现方法: 对于所有不等式约束(包括速度、加速度、分段时长平衡以及安全约束)C d C_d C d L 1 ( ⋅ ) L_1(\cdot) L 1 ( ⋅ )
离散化: 为了近似罚函数的值并确保整个轨迹满足约束,采用了离散采样点的方法进行约束。罚函数 I d I_d I d C i , j d C_{i,j}^d C i , j d ν j \nu_j ν j I d ( c , T ) = ς d ∑ i = 1 M ∑ j = 0 n T i n ν j L 1 ( C i , j d ( c , T ) ) I_d(\mathbf{c}, \mathbf{T}) = \varsigma_d \sum_{i=1}^{M} \sum_{j=0}^{n} \frac{T_i}{n} \nu_j L_1(C_{i,j}^d(\mathbf{c}, \mathbf{T})) I d ( c , T ) = ς d ∑ i = 1 M ∑ j = 0 n n T i ν j L 1 ( C i , j d ( c , T ))
这种罚函数方法是一种常见且有效的处理非线性不等式约束(如避障)的方式,它将约束项添加到目标函数 J 0 J_0 J 0 J s J_s J s
(2) 终点位置约束的处理方式(ALM)
与避障约束不同,终点位置约束(确保轨迹最终位置 ( x ~ f , y ~ f ) (\tilde{x}_f, \tilde{y}_f) ( x ~ f , y ~ f ) ( x f , y f ) (x_f, y_f) ( x f , y f )
约束的特殊性: 终点位置约束 C f ι ( c , T ) = x ~ f ( c , T ) − x f C_{f\iota}(\mathbf{c}, \mathbf{T}) = \tilde{x}_f(\mathbf{c}, \mathbf{T}) - x_f C f ι ( c , T ) = x ~ f ( c , T ) − x f e m a x e_{max} e ma x
使用 ALM 的原因: 文献指出,如果仅使用罚函数方法来处理终点位置约束,可能会有以下问题:
可能会改变轨迹的拓扑结构。
可能会减慢收敛速度。
优化结果可能无法满足所需的精度(最大误差 e m a x e_{max} e ma x
Q7.换挡点需要初始解提供吗?
根据提供的文献,该方法的核心在于其创新的运动状态(Motion State, MS)轨迹表示方法,它使得优化器能够自主地确定这些换挡点,而不需要初始解的预先指定。
(1) 换挡点的优化机制(自主确定)
该框架通过运动状态(MS)轨迹表示方法来建模前进和后退运动。
轨迹表示基础: MS 轨迹不是直接在笛卡尔坐标系 ( x , y ) (x, y) ( x , y ) θ \theta θ s s s σ = [ θ , s ] T \sigma = [\theta, s]^T σ = [ θ , s ] T
速度与方向: 机器人的线速度 v x v_x v x s s s v x = s ˙ v_x = \dot{s} v x = s ˙
当 s ˙ > 0 \dot{s} > 0 s ˙ > 0
当 s ˙ < 0 \dot{s} < 0 s ˙ < 0
当 s ˙ = 0 \dot{s} = 0 s ˙ = 0
避免奇异性实现平滑过渡: 这种基于运动状态的参数化具有显著的优点,即避免了非完整动力学引起的奇异性。在传统的基于微分平坦性(Differential Flatness, DF)的方法中,当运动方向改变时(即线速度 v x v_x v x
优化过程: 在 MS 轨迹中,前进和后退的改变被表示为θ − s \theta-s θ − s c \mathbf{c} c T \mathbf{T} T v x = s ˙ v_x = \dot{s} v x = s ˙ s ˙ \dot{s} s ˙
(2) 初始解是否需要提供换挡点
不需要。 这是 MS 轨迹相对于其他方法的关键优势之一。
与微分平坦性方法的对比: 文献指出,基于微分平坦性的方法(DF)需要依赖前端方法(如 Hybrid A*)来提供初始路径,以预先指定是前进还是后退运动。
MS 轨迹的通用性: 相比之下,MS 轨迹表示方法由于避免了奇异性,因此“一个统一的轨迹可以同时处理前进和后退运动,而不是由规划前端指定”。
尽管规划系统使用了 Jump Point Search (JPS) 来提供全局路径作为前端,以及使用了轨迹预处理,但这些步骤的目的是:
避免初始值导致的拓扑结构变化。
确保初始轨迹的积分终点更接近期望的终点。
生成更接近全局路径且更具动态可行性的初始轨迹。
预处理阶段主要关注位置和方向的平滑过渡,并满足运动学和加速度约束。由于 MS 轨迹本身固有的平滑性和对运动状态的直接参数化,它能够在优化过程中自主地决定最优的换向时机,无需前端路径预先指定运动方向。
未完待续。。。
内容太多了,今天就先学到这里,下一篇继续。