Vision Backbone(双视觉编码器)详解
一、什么是 Vision Backbone?
1.1 用生活中的例子来理解
想象你是一个人,你看到一张照片。你的眼睛负责接收光线,但真正"理解"这张照片的是你的大脑。 在深度学习中:
- 图像就像是照片
- Vision Backbone就像是"眼睛+初级视觉大脑"
- 它的任务是:把图像转换成计算机能理解的数字形式

1.2 为什么叫"Backbone"(骨干网络)?
Backbone 的英文意思是"脊椎骨"。就像脊椎骨支撑整个身体一样,Vision Backbone 是整个视觉系统的核心支撑部分,后续的其他模块都依赖它提取出来的视觉特征。
二、什么是"双"视觉编码器?
2.1 为什么要用两个编码器?
这就像是用两只眼睛看世界比用一只眼睛更好。 不同的视觉编码器有不同的"专长":
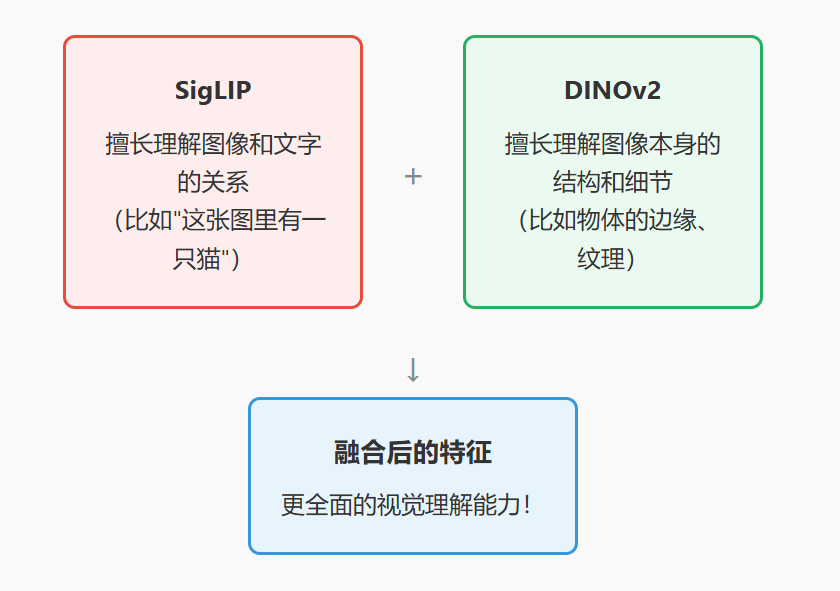
- SigLIP:擅长理解图像和文字的关系(比如"这张图里有一只猫")
- DINOv2:擅长理解图像本身的结构和细节(比如物体的边缘、纹理) 把两个编码器的结果结合起来,就能获得更全面的视觉理解能力!
2.2 两个编码器的特点对比
| 特点 | SigLIP | DINOv2 |
|---|---|---|
| 训练方式 | 图文对比学习 | 自监督学习 |
| 强项 | 理解"图像说的是什么" | 理解"图像长什么样" |
| 比喻 | 像一个会读图说话的人 | 像一个细致观察的画家 |
三、输入:图像是如何被处理的?
3.1 原始输入
OmniVLA 支持输入 2张图像:
- 当前图像:机器人当前看到的场景
- 目标图像:机器人要去的目标位置的图像
3.2 图像预处理步骤
 因为有两个编码器,每张图都要准备两份(格式略有不同)
因为有两个编码器,每张图都要准备两份(格式略有不同)
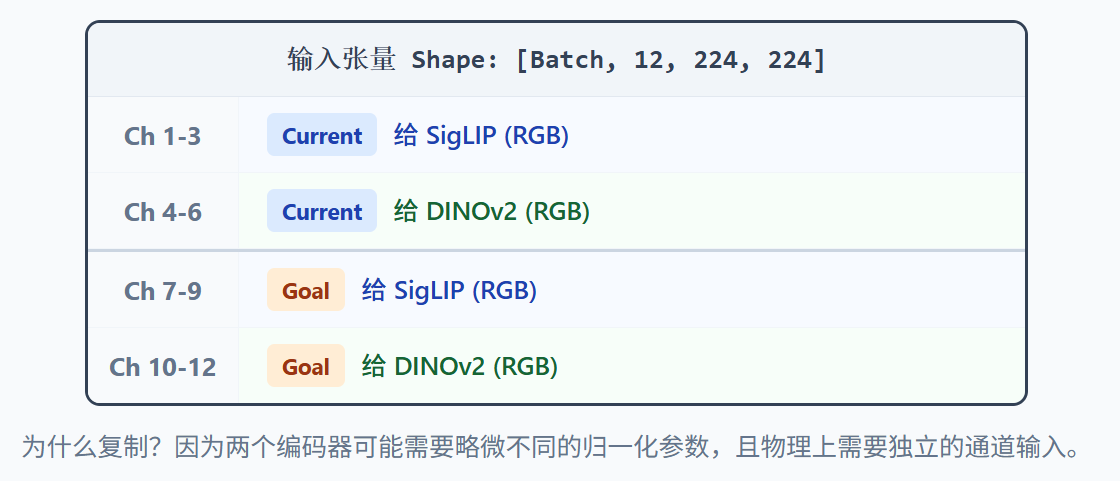
3.3 具体的输入格式
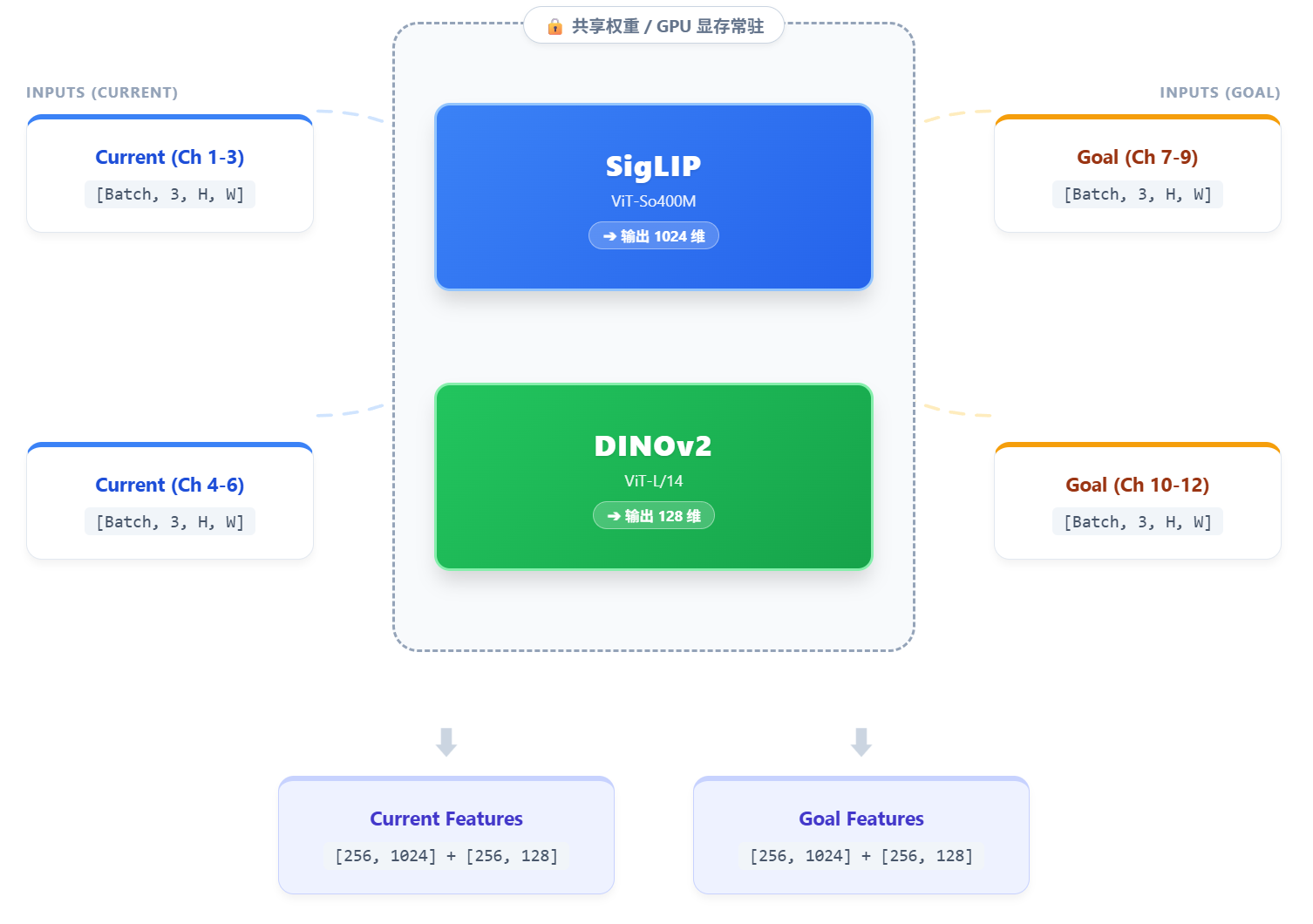
为了高效传输,系统将两张图像(每张处理成6通道)堆叠成一个巨大的 12通道张量。这是 Vision Backbone 的实际入口格式。
3.4 Current Image 和 Goal Image 的处理流程详解
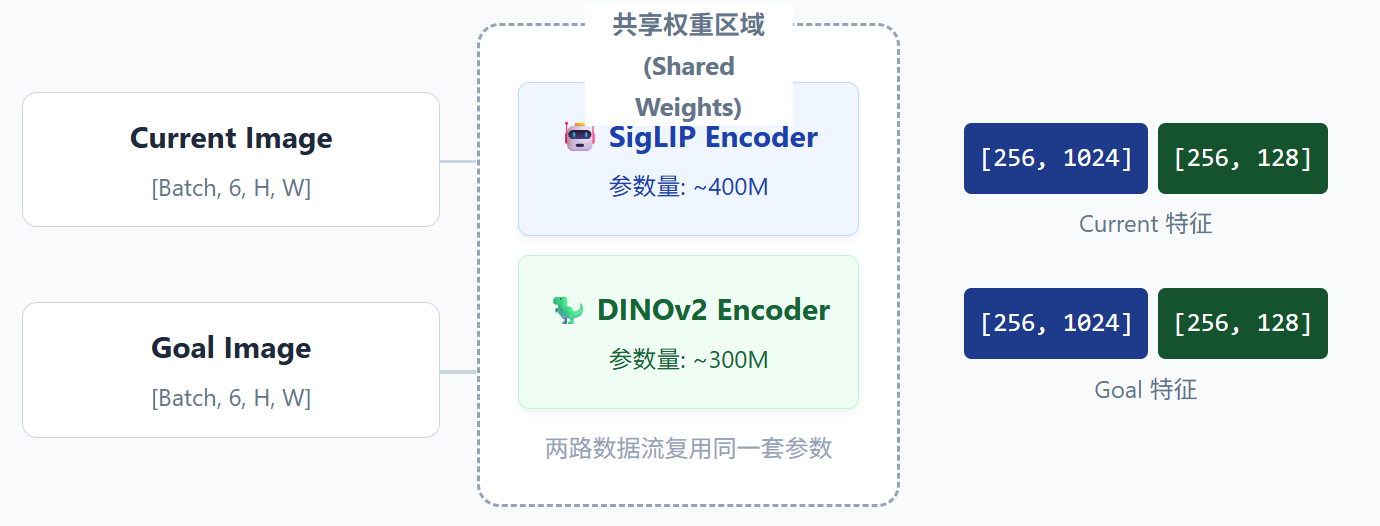
只有1个SigLIP和1个DINOv2,两张图像依次通过同一对编码器(权重共享),然后在输出后合并。
进入网络内部后,数据被拆分并流向对应的模型。关键点: SigLIP 和 DINOv2 在内存中各只有一份实例(权重共享),Current 和 Goal 图像依次通过它们。
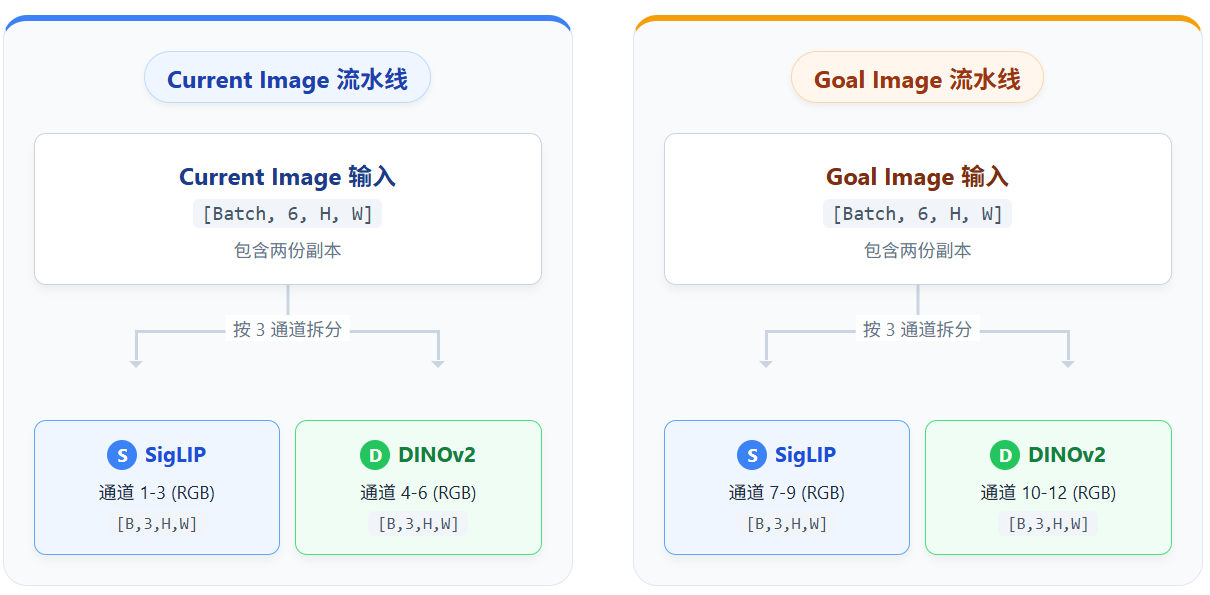
(1) 第一步:输入的准备
两张图像(Current Image 和 Goal Image)会被打包成一个张量输入:

(2) 第二步:分离图像
进入 Vision Backbone 后,首先把打包的数据拆开:

(3) 第三步:每张图像再分离给两个编码器
(4) 第四步:通过编码器(权重共享!)
重要:只有1个SigLIP和1个DINOv2,两张图像使用同一对编码器!
(5) 第五步:特征合并(两次拼接)
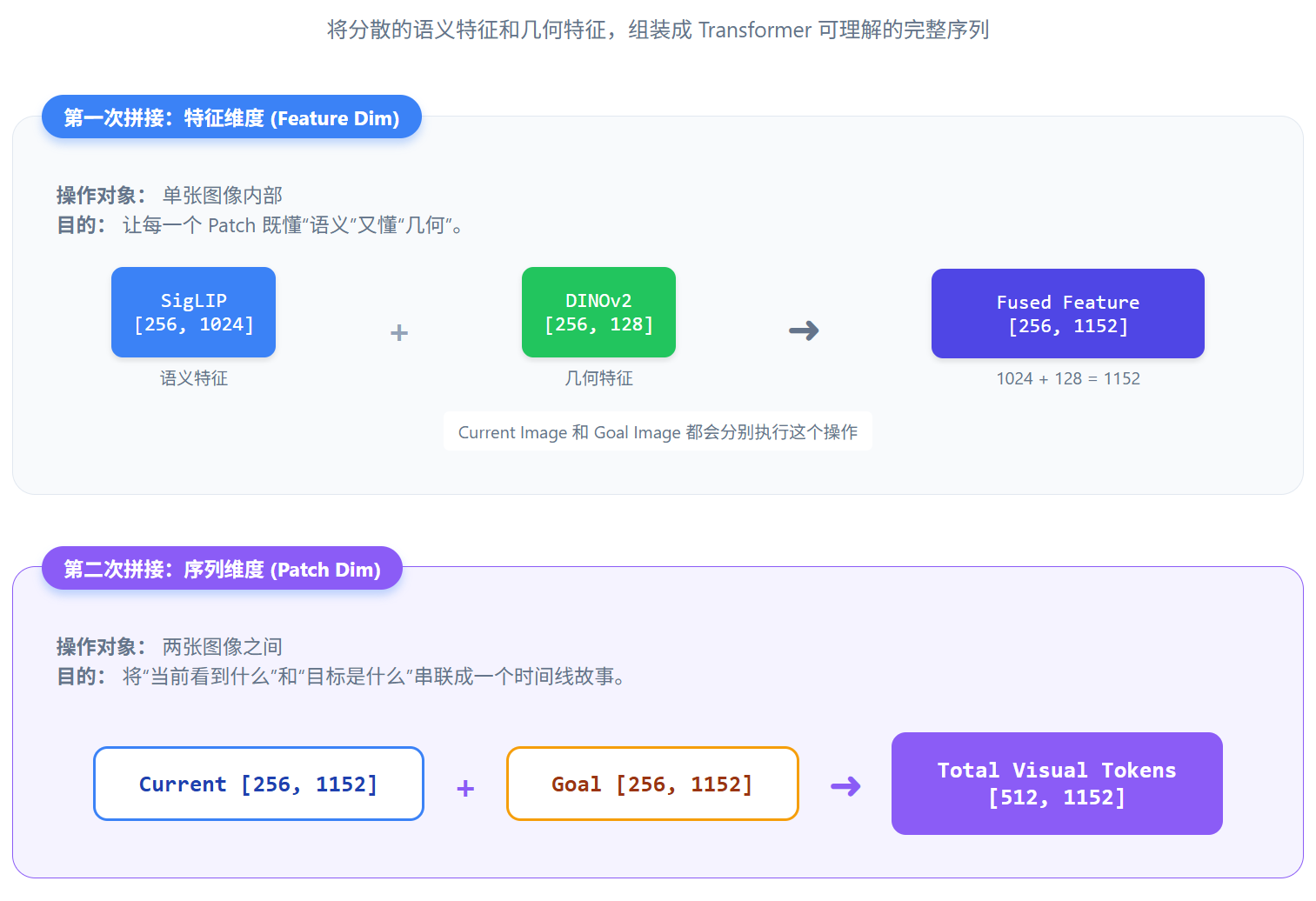

3.5 完整流程图

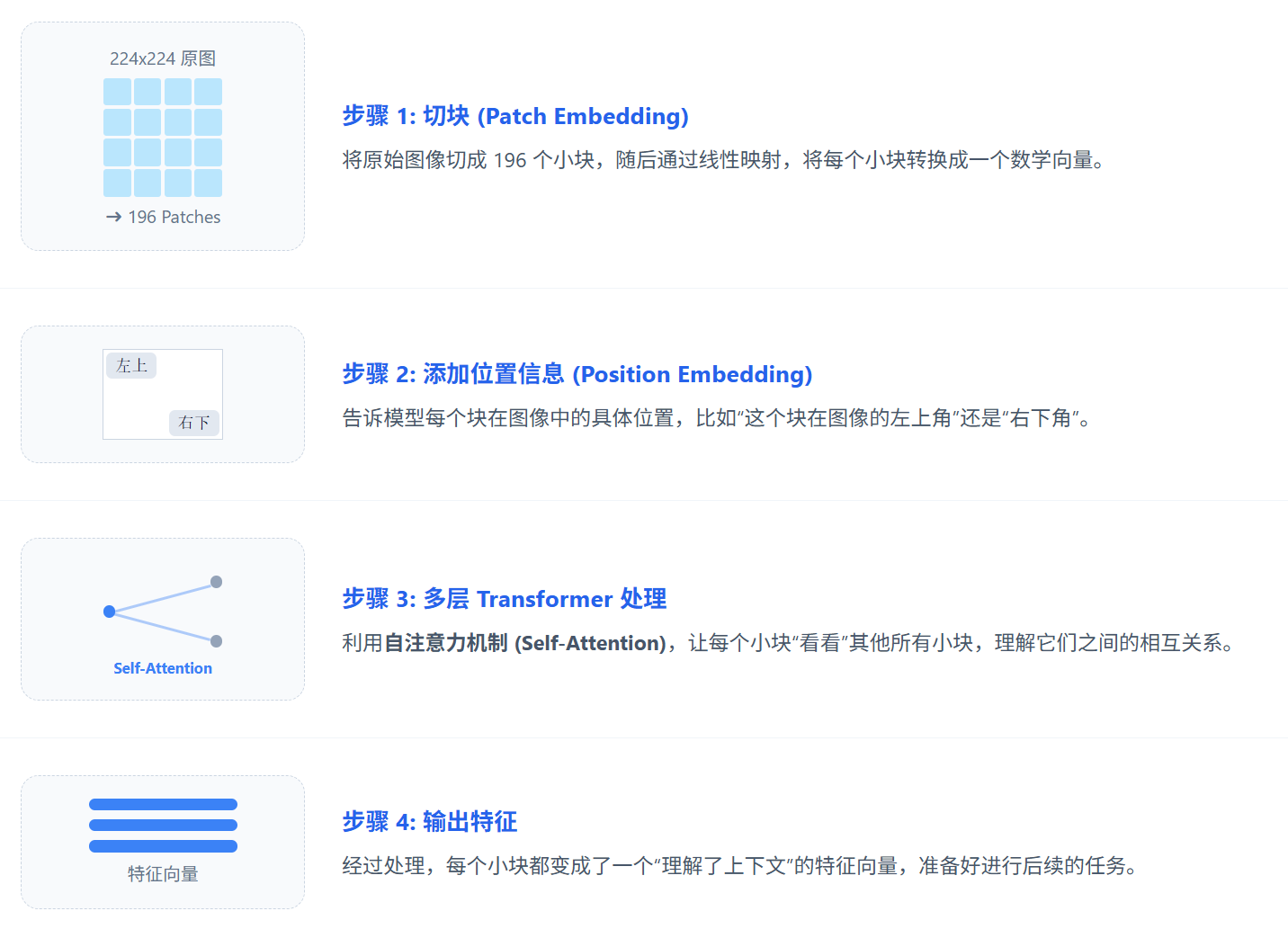
四、Vision Backbone 内部做了什么?
五、输出:提取出什么样的特征?
5.1 输出的形状
输出形状:[批次大小, patch数量, 特征维度],具体来说(以2张图像输入为例):

5.2 用更通俗的方式理解输出
想象一下:
- 输入是2张照片
- 输出是512个"小报告",每个报告有1152个数字 每个"小报告"描述的是图像中一个小区域的视觉特征:
- 这个区域是什么颜色?
- 有什么纹理?
- 像是什么物体的一部分?
- 和语言描述有什么关系?

六、总结
6.1 关键要点回顾
| 问题 | 答案 |
|---|---|
| Vision Backbone是什么? | 把图像转换成数字特征的"视觉理解器" |
| 为什么用双编码器? | 两个编码器各有专长,结合起来效果更好 |
| 输入是什么? | 2张图像(当前场景 + 目标场景) |
| 输出是什么? | 512个patch,每个有1152维特征向量 |
| 核心技术是什么? | Vision Transformer,把图像切块后用注意力机制处理 |

6.2 后续流程
Vision Backbone 提取的特征会被送入 Projector(投影器),把1152维的视觉特征投影到4096维(LLM的维度),然后才能和语言模型一起工作。