第一次看 ACT 项目,什么 Transformer、VAE、Mujoco、rollout,全是天书。但我没打算先把理论补完。太难,也太慢。 我的策略是:直接上手,边做边学,卡在哪就学到哪。这篇文章是我的第一站——带你一起看懂 ACT 项目的整体架构,了解它的核心模块和流程。开始前,我列了 本文出现的18 个关键词,是我一开始完全搞不懂的。你可以先扫一眼,如果不认识的超过 10 个,那我们就是同路人,可以放心往下看了。
先看项目代码的流程图:
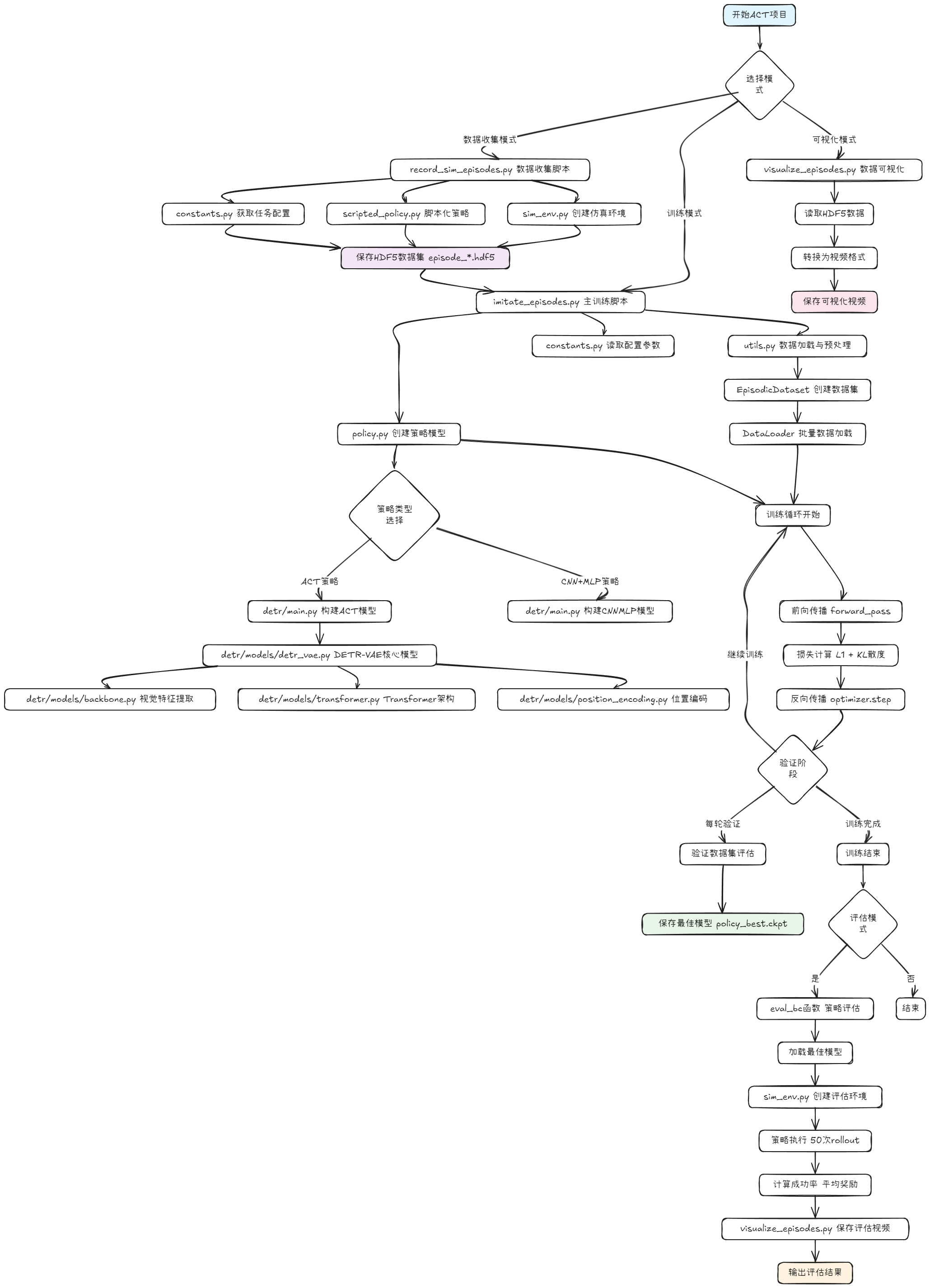
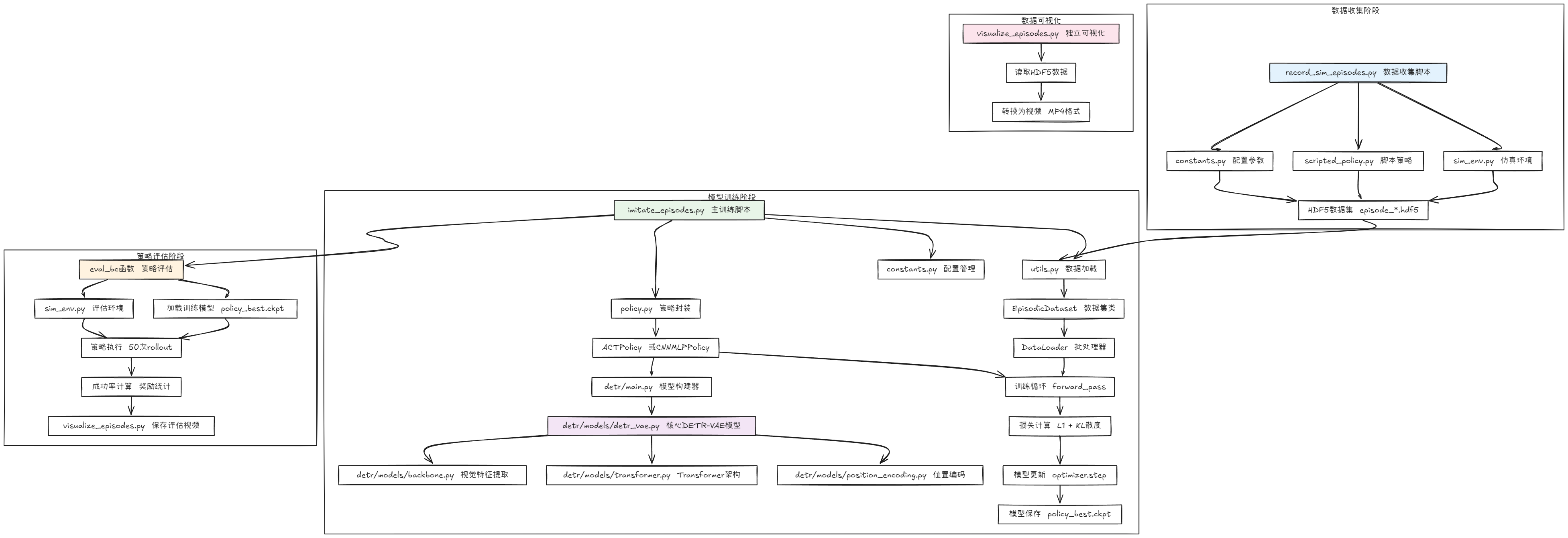
这是这个系列的第二篇正式文章,预计整个学习周期是1个月,同道中人,请关注收藏,不要掉队。
| 关键词 | 通用含义 | ACT 项目中的含义与作用 | |
|---|---|---|---|
| 1 | conda | Python 环境与依赖管理工具 | 用于创建独立环境,安装项目依赖(PyTorch、dm_control 等) |
| 2 | policy | 状态到动作的映射函数,策略网络 | 一个基于 Transformer 的神经策略网络,学习从观测到动作的映射 |
| 3 | Transformer | 一种基于注意力机制的序列建模神经网络架构 | 建模动作历史序列,实现动作 chunk 的生成 |
| 4 | 检查点 | 模型训练过程中的保存文件 | 保存 .pt 文件形式的模型参数,用于恢复或部署 |
| 5 | CNN+MLP | 卷积神经网络用于特征提取,MLP 进行输出 | CNN 提取图像特征,MLP 用于动作预测输出 |
| 6 | L1损失 | 预测值与真实值间的绝对误差 | 衡量预测动作与专家动作的差异,用于模仿学习训练损失 |
| 7 | KL散度损失 | 衡量两个概率分布之间的差异,常用于 VAE | 用于约束视觉 latent 特征接近正态分布,稳定编码器训练 |
| 8 | 推理 | 使用训练好模型进行预测 | 用于从策略网络中生成动作序列(无梯度) |
| 9 | detr | DETR(Detection Transformer)目标检测网络 | 提取图像特征 token,作为策略网络输入 |
| 10 | episode | 一段完整的状态-动作轨迹 | 单个任务轨迹(专家演示或策略执行),存储为 h5 文件 |
| 11 | HDF5格式 | 用于高效存储多维数据的文件格式 | 用于保存演示数据(观测、动作、奖励等) |
| 12 | Mujoco物理引擎 | 高精度机器人仿真引擎 | 提供 dm_control 支持的仿真环境,模拟双臂操控 |
| 13 | 专家演示 | 人或规则生成的高质量示范行为轨迹 | 由 scripted_policy.py 生成,作为训练模仿学习的数据 |
| 14 | VAE模型 | 变分自编码器,生成潜变量分布 | 与 DETR 联合编码图像观测,输出 latent vector 供策略使用 |
| 15 | backbone | 神经网络的主干结构,通常指 CNN | ResNet 作为图像主干网络,提取关键图像区域特征 |
| 16 | 反向传播 | 通过梯度传播优化模型参数的算法 | 模仿训练中用于更新策略参数,减小预测误差 |
| 17 | 前向传播 | 输入 → 输出的计算流程 | 将图像和状态输入模型,生成动作预测序列 |
| 18 | rollout | 策略在环境中执行生成一条轨迹 | 策略执行后的完整行为过程,用于可视化或评估 |
下边是文件的功能介绍:
| 文件名 | 说明 |
|---|---|
README.md | 项目简介与运行说明,建议先阅读 |
conda_env.yaml | 推荐的 Conda 环境依赖配置 |
constants.py | 全局常量配置,如文件路径、任务参数等 |
ee_sim_env.py | EE(末端执行器)仿真环境定义 |
imitate_episodes.py | 模仿学习训练主程序 |
record_sim_episodes.py | 模拟环境中记录演示数据 |
scripted_policy.py | 内置的脚本策略,用于收集示范数据 |
sim_env.py | 核心仿真环境类(多机臂物理模拟) |
policy.py | Transformer policy 的实现(ACT 主体) |
utils.py | 通用工具函数,如数据处理、转换等 |
visualize_episodes.py | 将动作序列或策略生成的视频可视化 |
1. imitate_episodes.py(主训练文件)
作用:
- 项目的主入口文件,负责模型的训练和评估
- 管理整个训练流程:数据加载、模型训练、验证、保存检查点
- 处理命令行参数,配置训练参数
- 在仿真环境中评估训练好的策略 调用关系:
- 调用 utils.py 中的 load_data() 加载训练数据
- 调用 policy.py 中的 ACTPolicy 或 CNNMLPPolicy 创建策略模型
- 调用 constants.py 获取任务配置和常量
- 调用 sim_env.py 中的 make_sim_env() 创建仿真环境
- 调用 visualize_episodes.py 中的 save_videos() 保存评估视频
2. policy.py(策略适配器)
作用:
- 策略模型的封装层,提供统一的接口
- 定义了两种策略:ACTPolicy(基于Transformer)和 CNNMLPPolicy(基于CNN+MLP)
- 处理训练时的损失计算(L1损失 + KL散度损失)
- 处理推理时的动作预测 调用关系:
- 调用 detr/main.py 中的 build_ACT_model_and_optimizer() 构建DETR-VAE模型
- 被 imitate_episodes.py 调用来创建和使用策略
3. constants.py(配置常量)
作用:
- 全局配置文件,定义项目的各种常量和参数
- 包含仿真任务配置(Transfer Cube、Insertion任务)
- 定义机器人物理参数(关节名称、夹爪位置限制等)
- 提供夹爪位置和关节角度的归一化/反归一化函数 调用关系:
- 被所有其他文件导入使用,提供配置参数
- 特别被 sim_env.py 和 ee_sim_env.py 用于机器人控制
4. utils.py(工具函数库)
作用:
- 数据处理核心模块,负责数据集的加载和预处理
- 定义 EpisodicDataset 类,用于加载HDF5格式的episode数据
- 提供数据归一化统计信息计算
- 包含环境工具函数(如随机位置采样)
- 提供通用辅助函数(字典处理、随机种子设置等) 调用关系:
- 被 imitate_episodes.py 调用进行数据加载
- 被 record_sim_episodes.py 调用进行环境采样
5. sim_env.py(关节空间仿真环境)
作用:
- 仿真环境的核心定义,基于Mujoco物理引擎
- 定义双臂机器人的关节空间控制环境
- 实现两个主要任务:TransferCubeTask(传递立方体)和 InsertionTask(插入任务)
- 处理机器人状态观测(关节位置、速度、图像)
- 定义奖励函数和任务成功条件 调用关系:
- 被 imitate_episodes.py 调用创建评估环境
- 被 record_sim_episodes.py 调用创建数据收集环境
- 调用 constants.py 获取机器人参数
6. ee_sim_env.py(末端执行器空间仿真环境)
作用:
- 另一种控制方式的仿真环境,使用末端执行器(End-Effector)空间控制
- 与 sim_env.py 类似,但控制空间不同(笛卡尔坐标而非关节角度)
- 更接近人类直觉的控制方式 调用关系:
- 与 sim_env.py 类似的调用关系
- 提供另一种控制接口选择
7. record_sim_episodes.py(数据收集)
作用:
- 数据收集工具,用于录制专家演示数据
- 可以收集脚本化策略或人工操作的演示数据
- 将收集的数据保存为HDF5格式,供训练使用 调用关系:
- 调用 sim_env.py 或 ee_sim_env.py 创建环境
- 调用 scripted_policy.py 中的脚本化策略
- 调用 utils.py 中的环境工具函数
8. visualize_episodes.py(可视化工具)
作用:
- 数据可视化工具,将HDF5数据集转换为视频
- 帮助用户查看收集的数据质量
- 可视化训练好的策略执行过程 调用关系:
- 被 imitate_episodes.py 调用保存评估视频
- 独立使用来可视化现有数据集
9. scripted_policy.py(脚本化策略)
作用:
- 基准策略实现,提供手工编写的策略作为对比
- 用于生成专家演示数据
- 包含Transfer Cube和Insertion任务的脚本化解决方案 调用关系:
- 被 record_sim_episodes.py 调用生成演示数据
- 调用 utils.py 中的环境工具函数
10. detr/models/detr_vae.py(核心模型)
作用:
- ACT模型的核心实现,基于DETR架构的VAE模型
- 结合了Transformer、VAE和视觉特征提取
- 实现动作序列的条件生成
- 支持多相机输入和机器人状态输入 调用关系:
- 调用 detr/models/backbone.py 进行视觉特征提取
- 调用 detr/models/transformer.py 实现Transformer架构
- 被 detr/main.py 调用构建完整模型