1.开篇:ACT的CVAE架构解析
深入学习Action Chunking with Transformers (ACT)算法,从机器人操作的误差累积问题出发,详细解析动作分块、时间平滑和CVAE等关键技术,并通过代码实践理解ACT的完整实现。
哎嗨哎嗨~,干货来了!ACT系列的第一篇文章,先来了解一下整个模型的框架。
想象一台机器人,正尝试用两只机械手像人一样执行一个精细活儿--比如打开一个小调味品的杯盖。你会发现,对机器人而言,这远比看上去难:哪怕指尖位置偏差了毫米级别,杯盖就可能滑脱。一直以来,只有那些价格高昂、装备精密传感器并经过严苛校准的高级机器人才能应付这样的任务。那么,有没有办法让廉价的机器人也干成这件事呢? 带着这个疑问,我们引出今天的主角--Action Chunking with Transformers (ACT)
 文章不包含任何公式,主要通过实际问题,逐步引入相关方法,一步一步探得ACT的全貌,我希望即便没有任何基础朋友,也能看明白,不信你试试。
文章不包含任何公式,主要通过实际问题,逐步引入相关方法,一步一步探得ACT的全貌,我希望即便没有任何基础朋友,也能看明白,不信你试试。
这套系统有叫 ALOHA,是“低成本开源双手远程操作硬件”的缩写。ALOHA 包含两对机械臂:一对是主臂,由人直接用手控制;另一对是从臂, 会实时模仿主臂的动作。一位操作员站在ALOHA旁边,抓住主臂演示如何执行任务,比如对准插座插入一节电池。与此同时,从手臂精确地复制这些动作,就像机器人的另一只手在照镜子。整个演示过程不需要复杂的程序或遥控器。

1.累计误差问题的引入
有了 ALOHA这套硬件系统,我们能轻松获取大量人演示机器人的数据——相当于手把手教机器人怎么做。那么接下来,是否只要让机器人模仿这些演示就万事大吉了呢?事情没有这么简单。这里有一个模仿学习的陷阱需要解释:错误累积。假设机器人要按照演示做一连串动作,它每走一步都尽量模仿人。但现实很骨感:第一次动作也许就有点偏差,位置不对或者力度不够。这个小偏差会导致机器人下一步所处的状态和原来的演示不一样了——就像走路踏偏一步,后面每一步轨迹都跟着歪。于是机器人第二步会更偏,第三步离谱更多……误差像雪球一样越滚越大,任务失败。这个现象称作“复合误差”:模型一点点小错误累计起来,可能让长串动作任务彻底走样 。对于我们这些精细操作任务,执行过程动辄上百步,如果每步都可能有小错,那累计起来失败几率就很高。如何解决这个问题?ALOHA的作者提出了解决方案:动作分块法(Action Chunking)。
2.动作块法-->解决累计误差
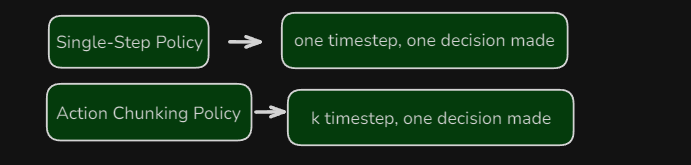
什么是动作块法呢?通俗的打个比喻,一个人在下棋,他每次只考虑当前需要怎么走。想一步走一步。另外一个人,每次会思考未来4步棋怎么走,然后就不再思考,一直等到这四步棋都走完了,再去思考接下来的四步棋怎么走。

让我们对比来看一下,原来的方式是单步策略,一个时间步,只做一个决策。而动作块策略,就是k个时间步,做一个决策。
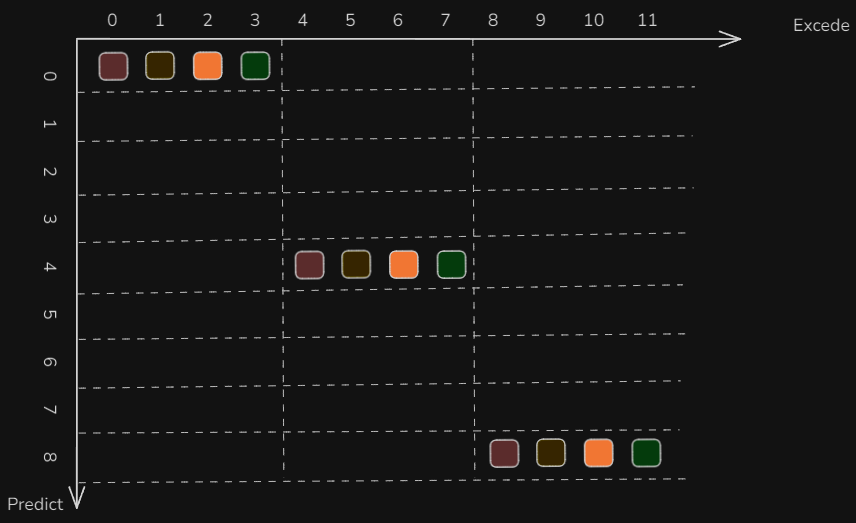
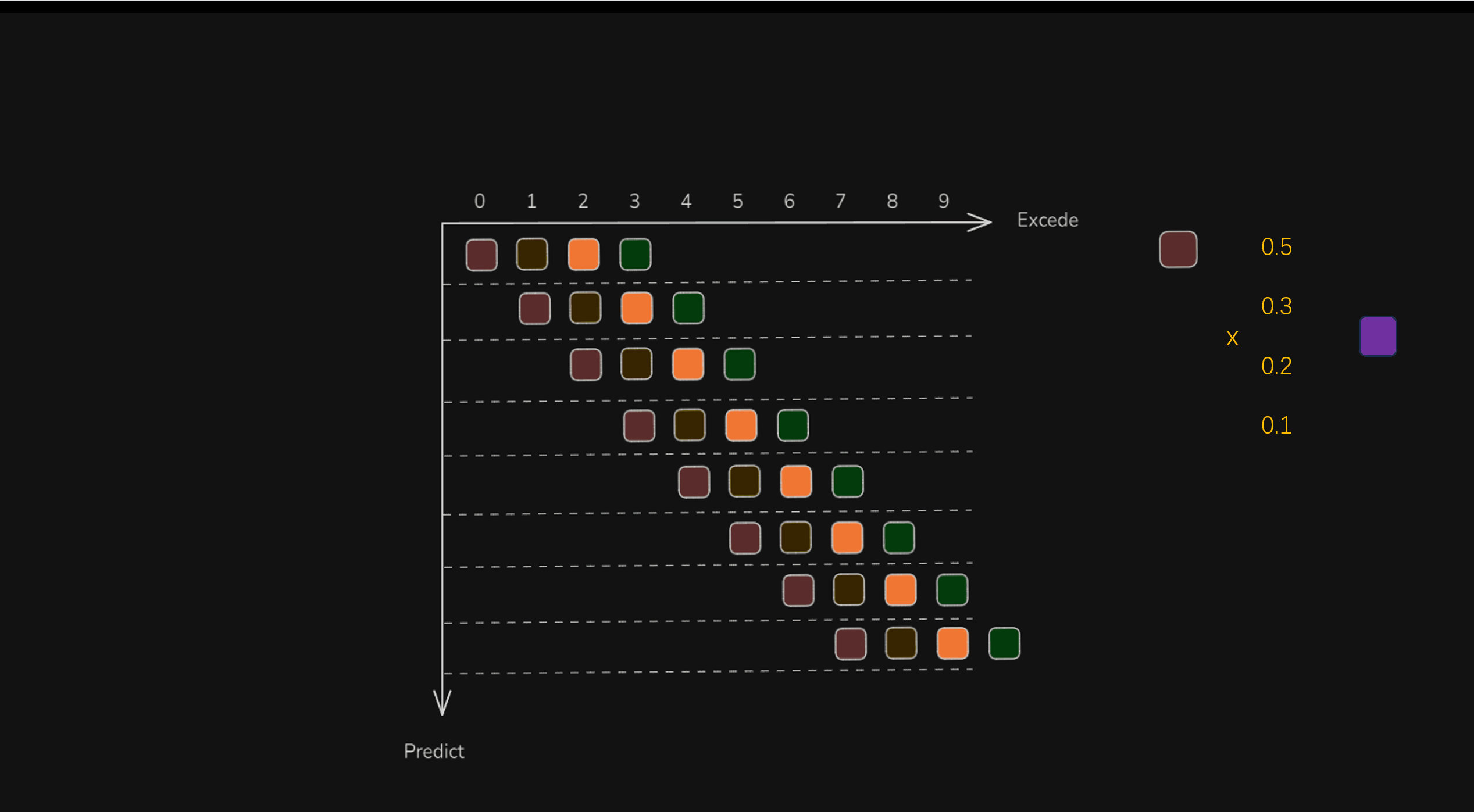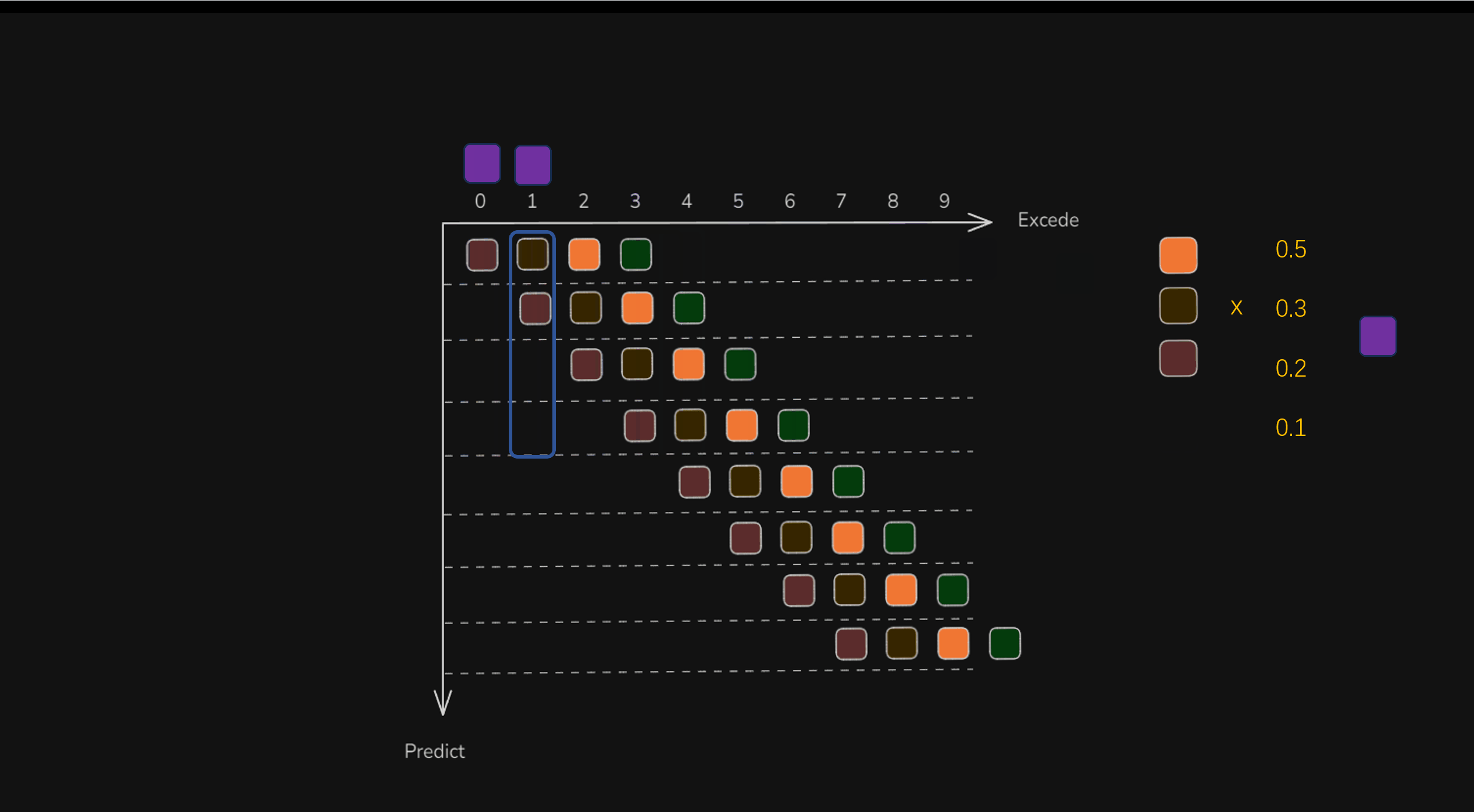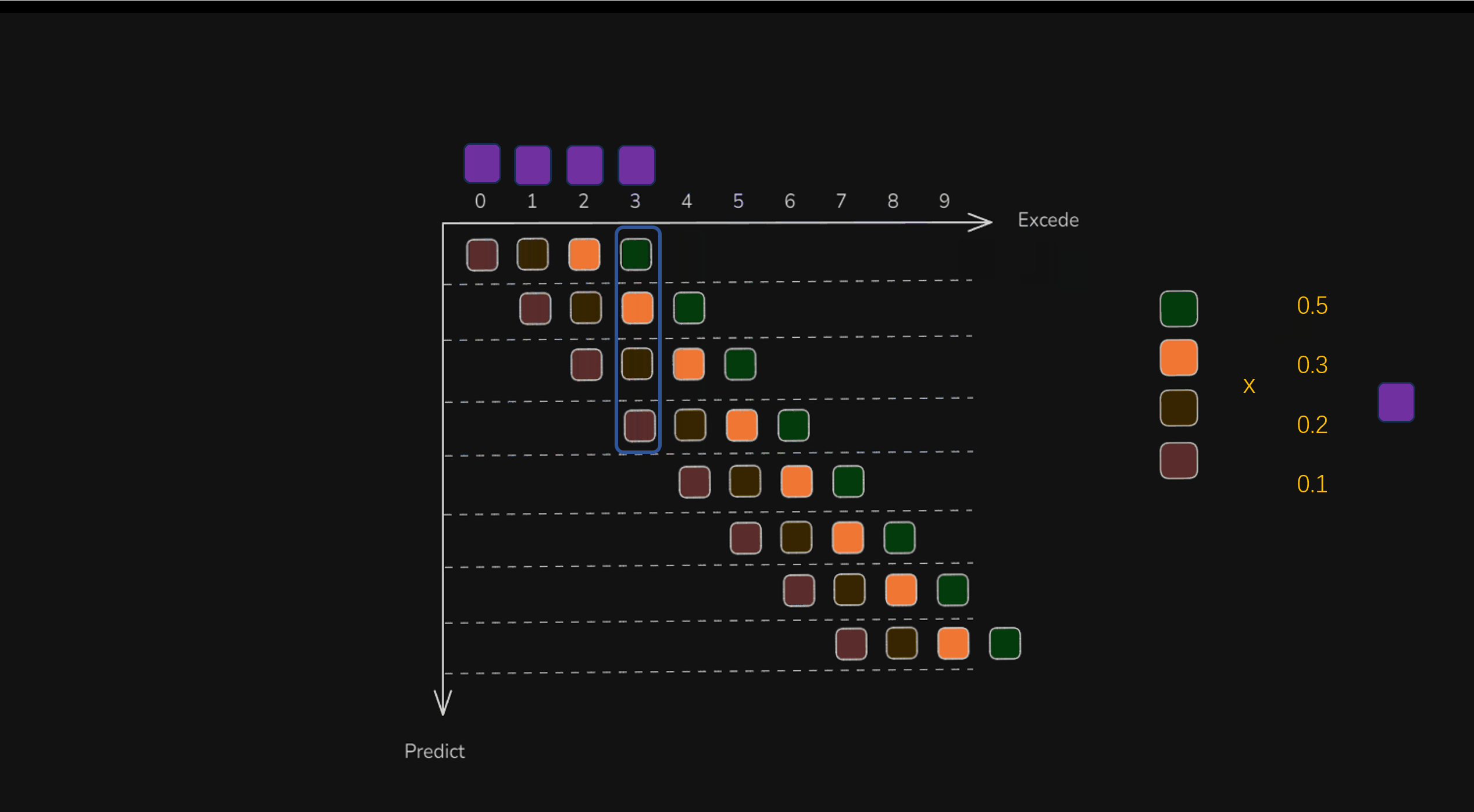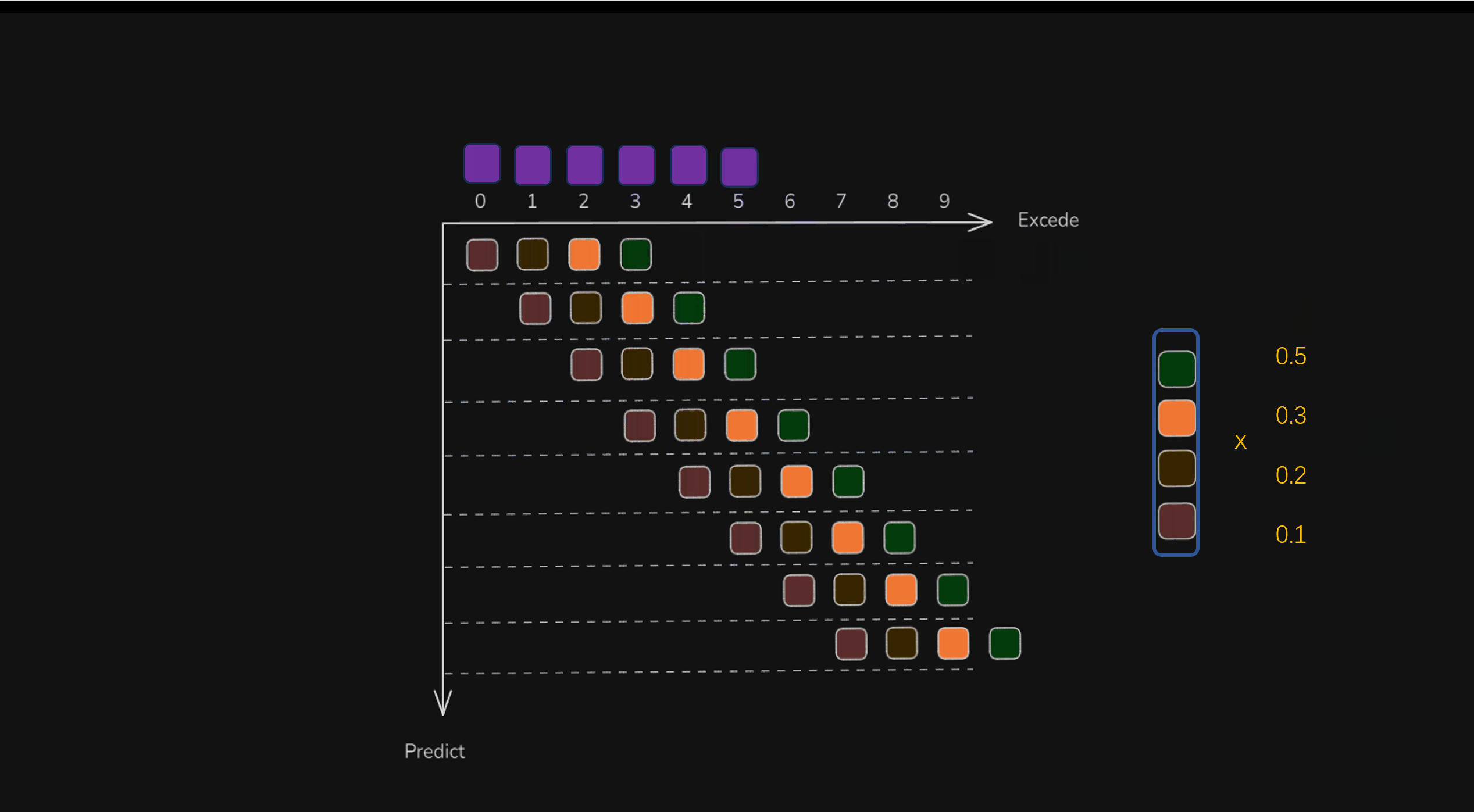
 让我们把目光聚焦在下图的纵轴上,t=0的时候,做了一次决策,或者说规划了4个动作,这四个动作可以让机器人去执行,横轴就是机器人的执行时间。在纵轴t=4的时候,机器人又做了一次决策,产生了四个动作。在纵轴t=8的时候,机器人又做了一次决策,产生了四个动作。通过动作分块的方式,做了3次决策,产生了12个动作,机器人可以从t=0执行到t=11(横轴)。
让我们把目光聚焦在下图的纵轴上,t=0的时候,做了一次决策,或者说规划了4个动作,这四个动作可以让机器人去执行,横轴就是机器人的执行时间。在纵轴t=4的时候,机器人又做了一次决策,产生了四个动作。在纵轴t=8的时候,机器人又做了一次决策,产生了四个动作。通过动作分块的方式,做了3次决策,产生了12个动作,机器人可以从t=0执行到t=11(横轴)。
3.不够平滑问题引入
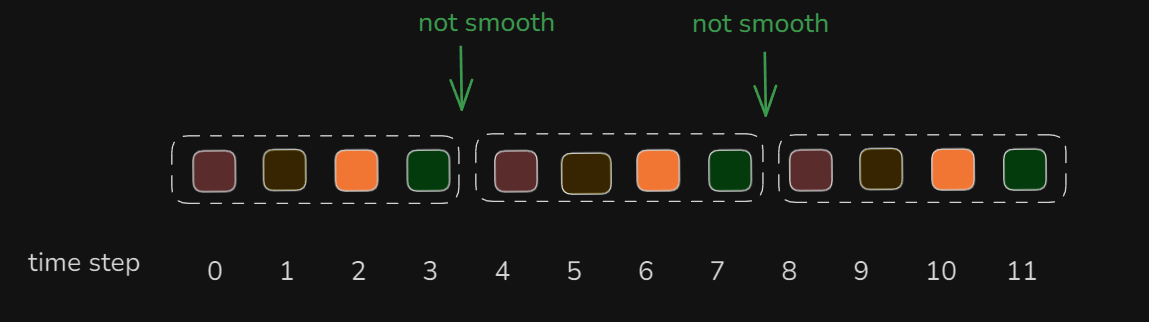
但是出现一个问题,这12个动作,被分成了三块,每块之间,动作可能不够平滑。这里就有点类似自动驾驶里的轨迹拼接了,相当于动作没有拼接。为了解决这个问题,作者提出了第二个关键概念:Temporal Ensembling
4.Temporal Ensembling-->解决平滑问题
Temporal Ensembling 是一个通用的、在半监督学习领域较常见的技术概念,用来做时间平滑预测。按照我的理解,就是做一个加权平均。如果每一个预测时间步,都决策出了四个动作,那么就形成了下图,比如在纵轴t=1时得到的4个动作,有三个是跟t=0的在横轴上重叠的。这些重叠的动作,就可以加权平均,得到一个新的动作。
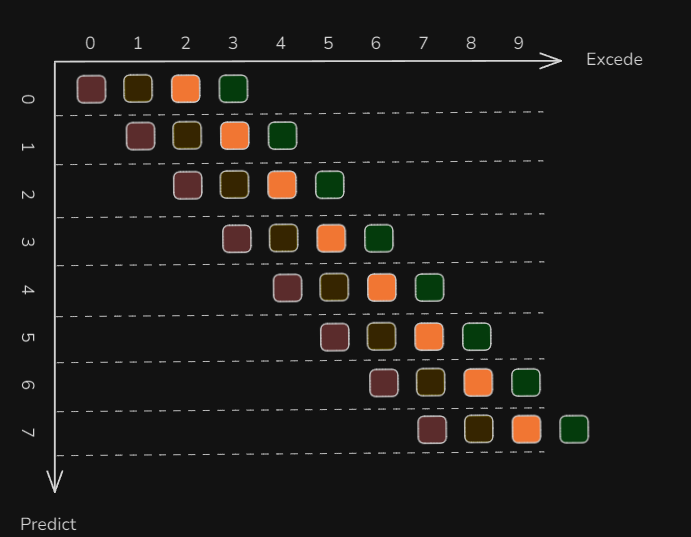 举个例子,在横轴时间t=3时,往纵向看,可以发现预测时间t=0~3都包含了一个动作。这四个动作,实在不同的时间决策出来的,但是都是用于在横轴t=3时来执行的,那么就可以对这四个动作(t∈(0,3))的时候,还不够4个动作)进行加权平均,得到最终的动作,即smooth之后的动作,作为最终机器人执行的动作(如下图中的紫色方块)。
举个例子,在横轴时间t=3时,往纵向看,可以发现预测时间t=0~3都包含了一个动作。这四个动作,实在不同的时间决策出来的,但是都是用于在横轴t=3时来执行的,那么就可以对这四个动作(t∈(0,3))的时候,还不够4个动作)进行加权平均,得到最终的动作,即smooth之后的动作,作为最终机器人执行的动作(如下图中的紫色方块)。
5.人类动作多样性问题的引入
解决了误差累计的问题,那么模仿学习还有别的问题吗?当然有,在模仿学习中,我们让机器人去“学人做事”,但人类做事的方式是多样的,就像:
“同样是把电池插进遥控器,张三和李四的做法可能略有不同,但都能成功。”
- 有人慢慢推进去,有人用快一点的速度。
- 有人先对齐左边,有人先对齐右边。
- 有时候手抖一下也不影响任务完成。 这些 小差异 让机器学起来很困惑,不清楚哪一种才是对的。简单来说就是,每一个人的风格不同,同一个人在演示同一个任务的时候,风格也可能不同。如何让机器人知道这些不同的风格呢?答案就是CVAE。
6.CVAE(条件变分自编码器)-->解决多样性的问题
人类演示的方式很多样,CVAE 就是教机器人去理解“人类风格”,这样即使做法不同,机器人也能学会做得又快又稳、不容易失败。它的结构如下:
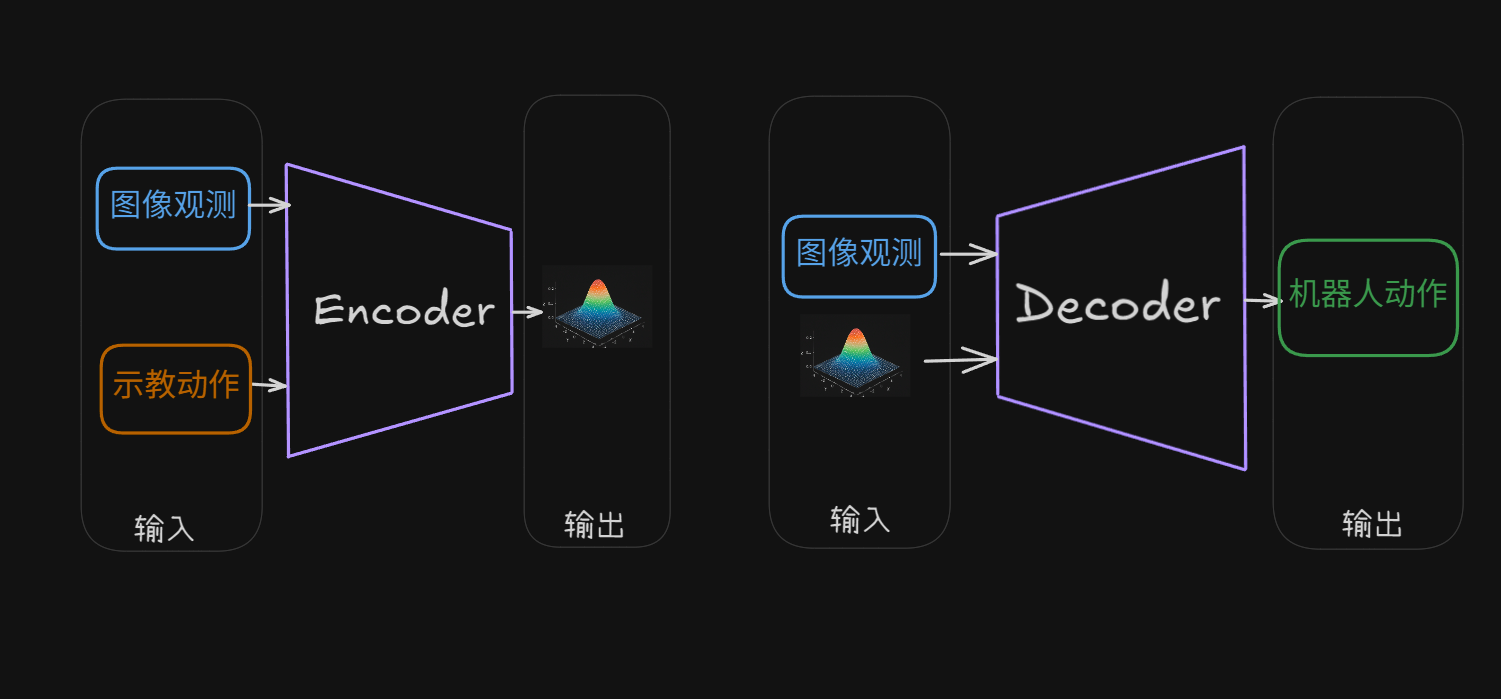 让我们从训练和部署两个阶段来简单说明这个CVAE。
让我们从训练和部署两个阶段来简单说明这个CVAE。
(1)训练阶段
编码器的作用是从人类演示中提取出潜变量,可以理解为上图中的正态分布。 解码器的作用是根据当前观测和风格变量(从正态分布中获得的),预测下一个动作序列(动作块)。 重构误差 + KL 散度一起训练这个系统,最后得到的核心产物就是解码器。
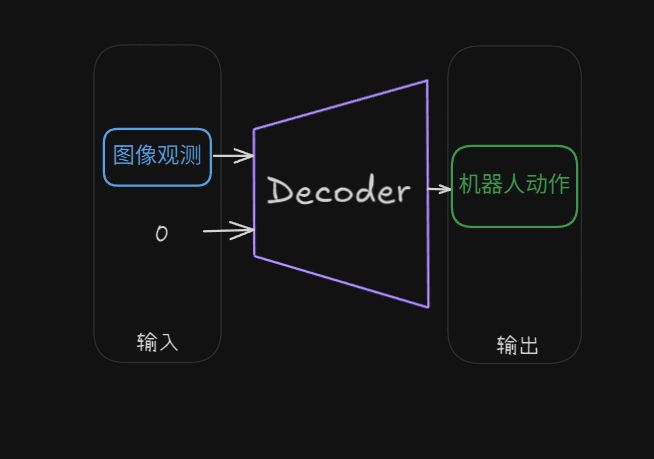
(2)部署阶段
部署到机器人上的就只有一个解码器,风格变量直接设置为0(默认风格):
7.如何实现Encoder和Decoder呢
再进一步学习encoder和decoder内部细节之前,让我们来总结一下剩余的问题:
- 机器人不能“只看当前画面”,很多时候你得知道之前干了啥,才知道接下来该干嘛
- 同时输入4 个摄像头图像 + 机器人关节角度 + CVAE 的风格向量,如何融合
- 需要一次性生成整段动作序列
- 还有其他问题,不一一列举 如果用学术话的语言总结,就如下表:
| ACT中的需求 | Transformer的能力 |
|---|---|
| 跨时序建模 | 自注意力机制,全局依赖建模 |
| 多模态融合 | 支持拼接图像、状态、风格输入 |
| 一次生成一段动作 | 支持序列生成(Seq2Seq) |
| 风格控制 | 条件生成(可引入 latent z) |
| 平滑控制输出 | 序列结构+重叠 chunk 平滑 |
之前的文章我也思考过,Transformer不是ACT的作者发明的,但是他却能够想到,把Transformer用在ACT中。因为作者非常清楚当前的问题是什么,带着问题去找解决方案。解决方案一直都在,只是发现问题的能力才是最重要的(非ACT作者观点,仅仅个人感悟)。
8.Transformer的引入 -->实现的Encoder和Decoder
Transformer是一个很复杂的东西,这里先不展开讲了,后续文章可以单独写一篇了,让我们来总结一下ACT的全貌:
(1)训练阶段结构:
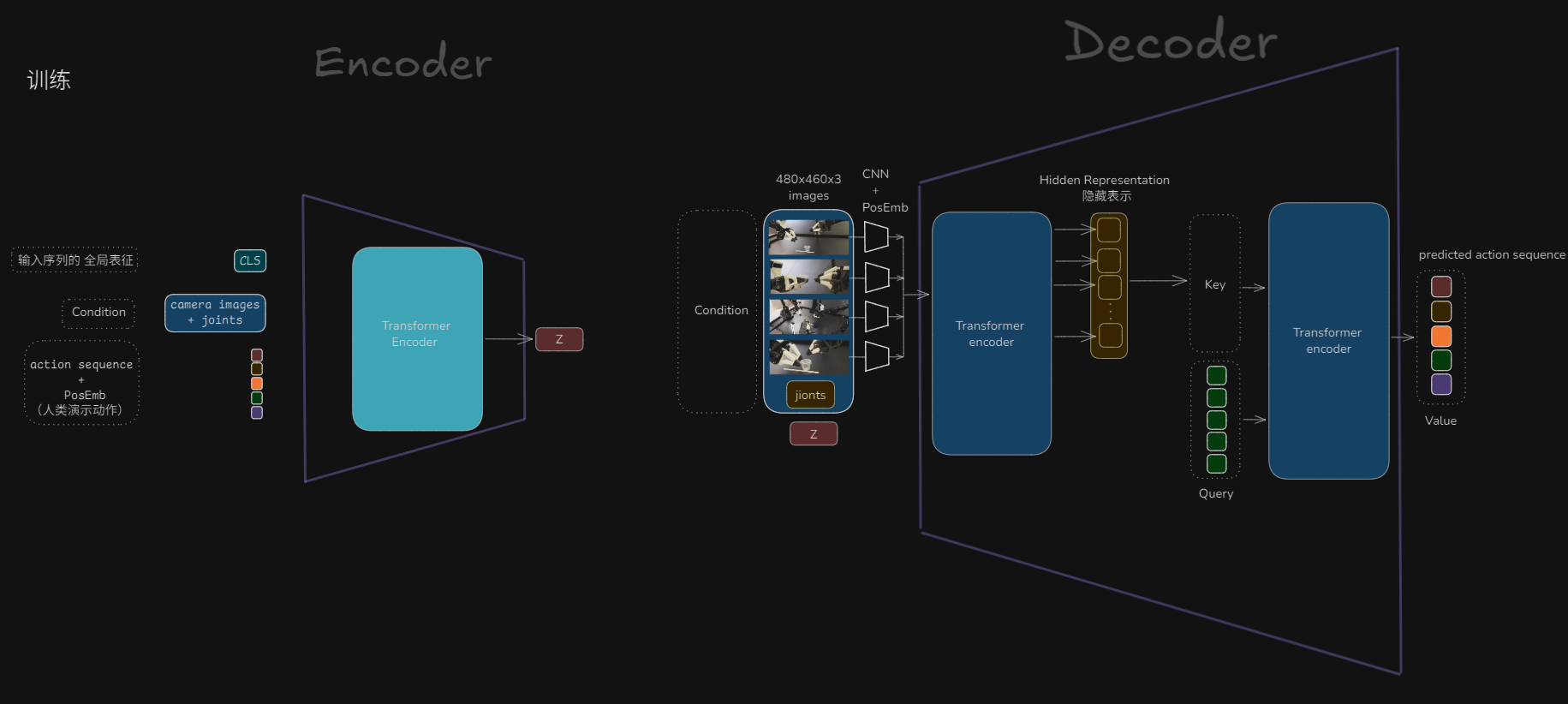 左侧为CVAE编码器,右侧为CVAE解码器
CVAE编码器的输入:
左侧为CVAE编码器,右侧为CVAE解码器
CVAE编码器的输入:
- CLS,暂时不用管
- 摄像机观测的图像+机器人关节(这个就是CVAE中的C)
- 人类演示动作 CVAE编码器的输出为
- 风格变量 CVAE解码器的输入:
- 摄像机观测的图像+机器人关节(这个就是CVAE中的C)
- 风格变量 CVAE解码器的输出
- 动作块
需要注意的是,在 ACT 中,CVAE 的解码器 是一个完整的 Transformer 编码器-解码器对,编码器处理复杂观察,解码器生成动作序列。因为单一Transformer解码器需要输入token逐步“翻译”动作,但原始图像信息结构复杂,不适合直接拼进去。
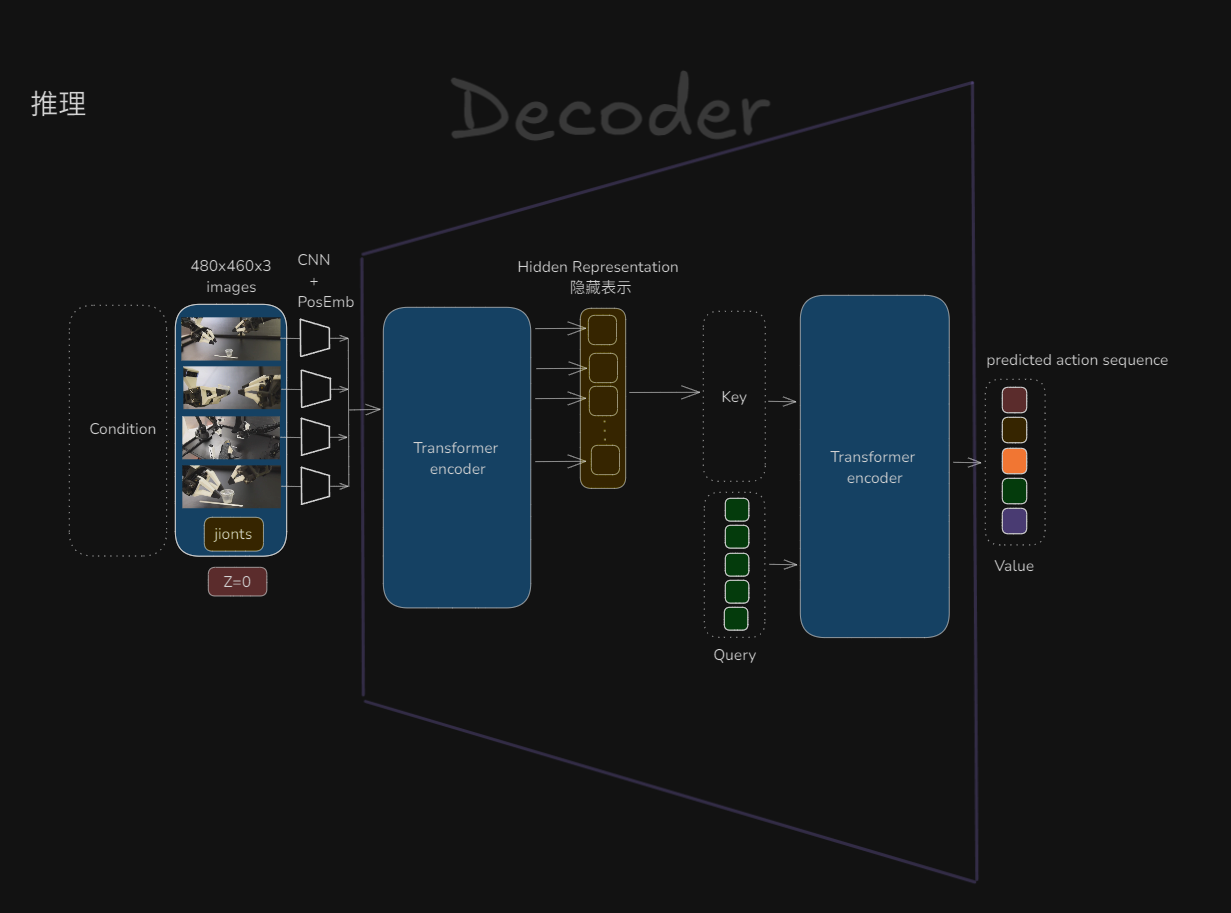
(2)推理阶段结构:
推理阶段只需要一个CVAE解码器,它由一个完整的 Transformer 编码器-解码器对构成。
在推理阶段,风格变量直接设置为0,表示标准风格。看一下解码器的内部细节,输入经过Transformer编码器压缩后,作为key,然后和Query一起作为输入,给到Transformer解码器,最后生成预测动作序列。这个就是Transformer中的QKV,这里不展开讲了。
9.理论学习结束-->代码初探
理论就到这里了,里面还有很多知识盲点和细节,永远也学不完,所以需要在干中学,开始看代码。
 整体代码量很少,才85行代码。这个跟我之前的印象就截然不同了,之前的工作中,都是c++项目工程,动不动就是几万行代码。先挑一个policy.py看一下。
整体代码量很少,才85行代码。这个跟我之前的印象就截然不同了,之前的工作中,都是c++项目工程,动不动就是几万行代码。先挑一个policy.py看一下。
(1)学习心得和习惯
我学习新代码的习惯是这样的,先让GPT用文字给我总结一下代码功能,还有涉及到神经网络、数学等基 本概念,然后再绘制出流程图,方便理解代码流程。然后再跟GPT沟通,让它绘制出时序图。当然,我之前python代码用的不多,很多语法不会,所以我会再要求GPT把代码中涉及到的语法知识点给我列出来。这样一顿沟通后,就可以学习这些代码了。 但是有个问题是,跟GPT沟通,让它输出文字总结,流程图,时序图,思维导图,知识点这五项内容,需要一遍一遍反复跟它提问,反复调整提示词,才能达到我想要的效果。然后下一次有新的代码需要让它讲解时,又要一遍一遍沟通,时间成本很高。
(2)自己开发个工具来辅助学习代码
所以我自己开发了个网页分析工具,可以一键生成我想要的内容。页面如下:
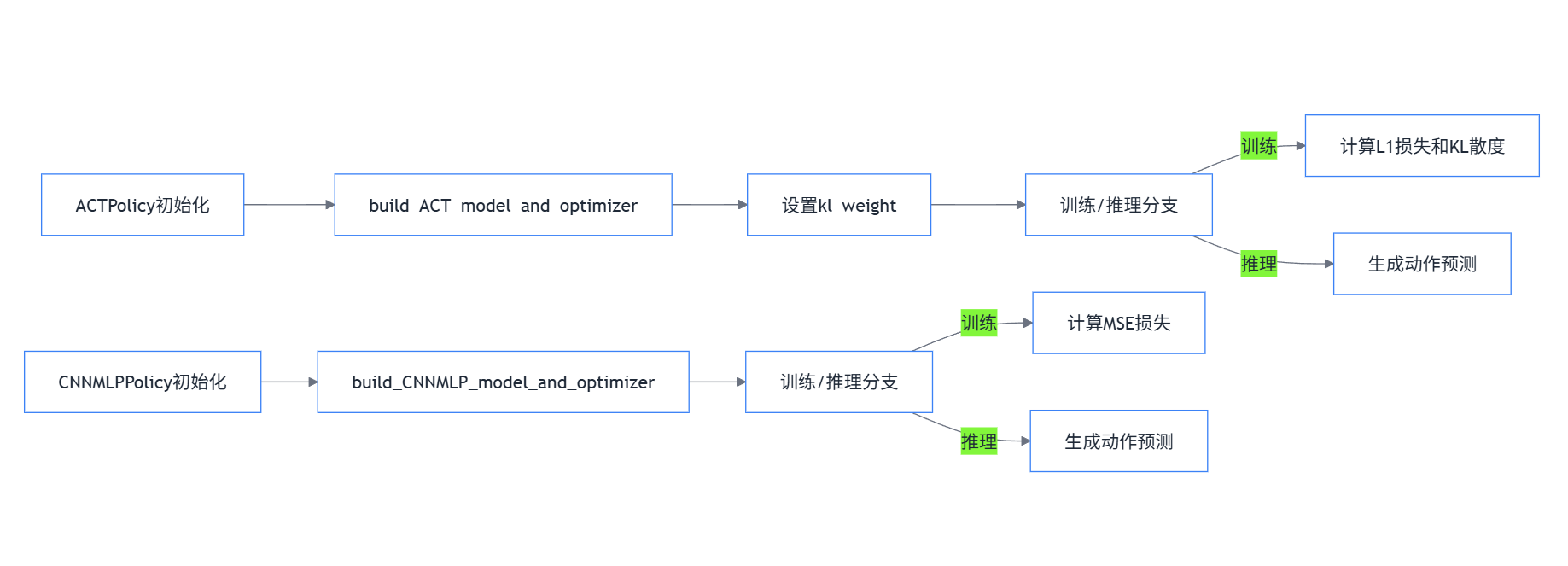
算法流程图:
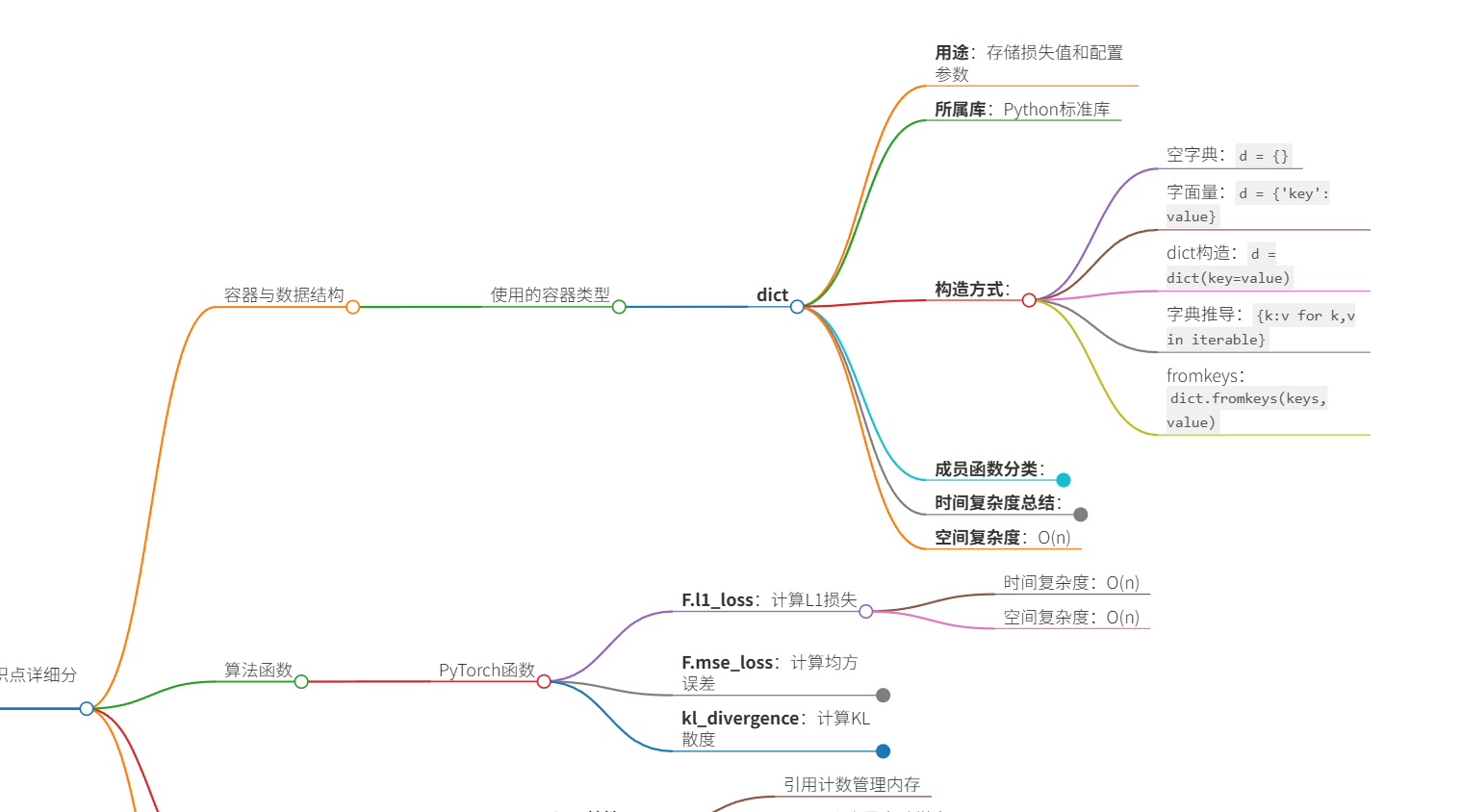
 语法知识总结:
语法知识总结:
下一篇将会正式开始学习ACT的代码部分,由于刚刚开发,还有很多需要优化的地方,欢迎大家测试以后提一些建议,我会修复bug和完善功能。