Chapter 2: 有限时域 LQR

目标:理解 Bellman 递推和 Riccati 方程,实现从"给定控制"到"求解最优控制"的跨越
2.1 从"评估"到"优化"
在 Chapter 1 中,我们只能做"评估"——给定控制序列,计算轨迹和代价。但我们真正想做的是找到最优的控制序列。
LQR(Linear Quadratic Regulator,线性二次调节器)是这个问题的线性特例,具有解析解。它是理解 iLQR 的基础。
2.2 LQR 问题定义
基础概念
LQR 处理的是线性动力学 + 二次代价的特殊情况。本文讲解的是参考跟踪(reference-tracking)形式的 LQR:

其中:
- 是状态转移矩阵
- 是控制输入矩阵
- 是状态代价矩阵(半正定)
- 是控制代价矩阵(正定)
- 是终端代价矩阵
- 是状态参考点(目标状态), 是控制参考点
参考跟踪 vs 调节器形式:当 时退化为标准调节器形式。后续推导中,Riccati 递推(求增益 )与参考点无关;参考点只影响控制律的应用:。
对应代码中的问题定义(include/lqr/finite_horizon_lqr_solver.hpp):
struct FiniteHorizonLQRProblem {
Matrix A; // 状态转移矩阵 (n×n)
Matrix B; // 控制输入矩阵 (n×m)
Matrix Q; // 状态代价矩阵 (n×n)
Matrix R; // 控制代价矩阵 (m×m)
Matrix Qf; // 终端代价矩阵 (n×n)
Vector state_reference; // 状态参考点
Vector control_reference; // 控制参考点
int horizon = 0; // 时域长度 N
};
我们要找一组控制序列 ,使系统从初始状态 出发,尽量靠近参考点 ,同时不消耗过多控制能量。
本步得到:一个 N 步全局优化问题。变量维度很高(n×N + m×N),直接求解不现实。 下一步要做:引入动态规划,把全局问题拆成 N 个单步问题。
2.3 LQR 动态规划的完整推导
下图为总览流程图:
 下图为核心推导细节,展示 Bellman 方程如何一步步变成 Riccati 递推和控制律
下图为核心推导细节,展示 Bellman 方程如何一步步变成 Riccati 递推和控制律

动态规划的核心思想是:最优策略的子策略也是最优的(最优性原理)。 动态规划的关键是从后往前思考:假设我们已经知道从第 步到终点的最优代价,那么在第 步该如何选择 ?
值函数
如果我们定义值函数(Value Function)为从第 步开始到终点的最小代价:
Bellman方程
 Bellman 方程(最优性原理),把 拆成"当前步代价 + 未来最优代价":
Bellman 方程(最优性原理),把 拆成"当前步代价 + 未来最优代价":
其中:
这就是 Bellman 方程——它把一个步优化问题递归地分解成了一系列单步优化问题。 含义:第 步的最优代价 = 当前代价 + 从下一状态出发的最优代价。
本步得到:Bellman 递推结构。 步全局优化 → 个单步 问题。 下一步要做:确定 的具体函数形式,才能真正求解。
二次型假设
 终端条件():没有后续代价了,只有终端代价:
假设每一步的 都保持二次型:
其中 是待求的对称正半定矩阵,终端条件:
终端条件():没有后续代价了,只有终端代价:
假设每一步的 都保持二次型:
其中 是待求的对称正半定矩阵,终端条件:
本步得到:值函数的参数化形式。求 转化为求矩阵 。 下一步要做:把假设代入 Bellman 方程,展开并对 求导。
二次型假设带入Bellman方程

将和动力学 代入 Bellman 方程: (这里有一个重要的注意点:当参考点是系统的平衡点(即 )时,交叉项消失,递推可以完全用偏差量 表示。)
这是关于 的 凸二次函数(因为 ),对 求导并令其为零:
整理:
本步得到:最优 关于 的线性方程。 下一步要做:解这个方程,得到反馈增益 。
解出增益与 Riccati 方程
 由于 且 ,矩阵 一定可逆。直接解出增益矩阵:
将最优 代回值函数,整理后得到 关于 的递推:
从 开始,逐步算出 ,同时得到每一步的 。
由于 且 ,矩阵 一定可逆。直接解出增益矩阵:
将最优 代回值函数,整理后得到 关于 的递推:
从 开始,逐步算出 ,同时得到每一步的 。
本步得到:两个核心公式 —— 增益 和 递推。注意它们只依赖 ,与参考点无关。 下一步要做:将增益应用到实际控制中。
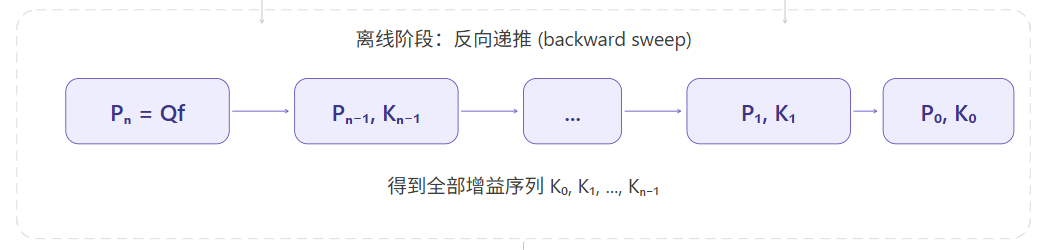
离线阶段:反向递推
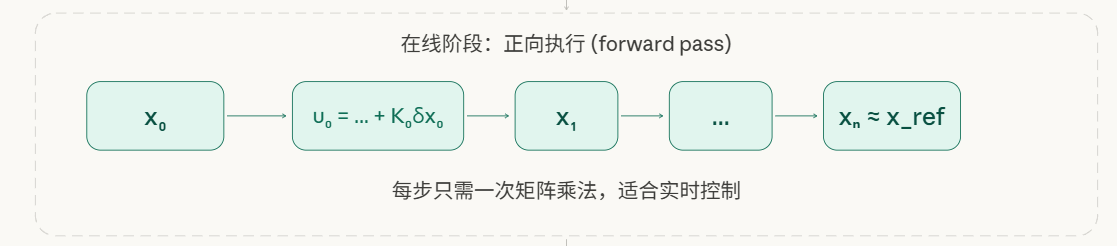
前向执行:实时计算控制量
 反向递推阶段(离线)已经算好了所有 。现在正向运行系统,得到最终控制律 :
每一步只需做一次矩阵乘法,不需要任何数值搜索或迭代优化,非常适合实时控制。
反向递推阶段(离线)已经算好了所有 。现在正向运行系统,得到最终控制律 :
每一步只需做一次矩阵乘法,不需要任何数值搜索或迭代优化,非常适合实时控制。

2.6 代码实现
Backward Pass:Riccati 递推
// src/lqr/finite_horizon_lqr_solver.cpp
void FiniteHorizonLQRSolver::Solve() {
// Step 1: 终端条件
riccati_matrices_.back() = problem_.Qf; // P_N = Q_f
// Step 2: 从 k=N-1 递推到 k=0
for (int k = problem_.horizon - 1; k >= 0; --k) {
const Matrix& P_next = riccati_matrices_[k + 1]; // P_{k+1}
// S = R + Bᵀ P_{k+1} B
const Matrix S = problem_.R + problem_.B.transpose() * P_next * problem_.B;
// K_k = -S⁻¹ Bᵀ P_{k+1} A
const Matrix rhs = problem_.B.transpose() * P_next * problem_.A;
feedback_gains_[k] = -S.ldlt().solve(rhs); // 用 LDLT 分解求解
// P_k = Q + Aᵀ P_{k+1} (A + B K_k)
riccati_matrices_[k] =
problem_.Q + problem_.A.transpose() * P_next * (problem_.A + problem_.B * feedback_gains_[k]);
}
is_solved_ = true;
}
Forward Simulate:闭环仿真
Trajectory FiniteHorizonLQRSolver::Simulate(const Vector& initial_state) const {
Trajectory trajectory(problem_.StateDim(), problem_.ControlDim(), problem_.horizon);
trajectory.State(0) = initial_state;
for (int k = 0; k < problem_.horizon; ++k) {
// 反馈控制律: u_k = u_ref + K_k (x_k - x_ref)
trajectory.Control(k) = Control(trajectory.State(k), k);
// 线性动力学: x_{k+1} = A x_k + B u_k
trajectory.State(k + 1) = problem_.A * trajectory.State(k)
+ problem_.B * trajectory.Control(k);
}
return trajectory;
}
Vector FiniteHorizonLQRSolver::Control(const Vector& state, int k) const {
const Vector state_error = state - problem_.state_reference;
return problem_.control_reference + feedback_gains_[k] * state_error;
}2.7 LQR 与 iLQR 的关系
LQR 是 iLQR 的"内核"。两者的关键区别:
| 特性 | LQR | iLQR |
|---|---|---|
| 动力学 | 线性 | 非线性 |
| 代价 | 二次 | 任意(用二次近似) |
| 求解方式 | 一次 backward + forward | 迭代:多次 backward + forward |
| Jacobian | 已知 | 需要在每次迭代时重新计算 |
iLQR 的核心思想:在当前轨迹处将非线性问题局部线性化/二次化,得到一个 LQR 子问题,求解后更新轨迹,如此反复迭代。
iLQR = 迭代地做以下事情:
┌──────────────────────────────────────────┐
│ 1. 在当前轨迹处线性化动力学 → A_k, B_k │
│ 2. 在当前轨迹处二次化代价 → Q, R 等 │
│ 3. 用 LQR 思路求解反馈增益 K_k, d_k │ ← 这一步和 LQR 几乎一样!
│ 4. 用增益更新轨迹 │
│ 5. 若未收敛,回到 1 │
└──────────────────────────────────────────┘
2.8 本章小结
我们从一个维度很高的全局优化问题出发,通过 Bellman 方程把它拆成 N 个单步问题;然后利用 LQR 的二次型结构,让每一步都有解析解(不用数值搜索);最终反向算完所有增益矩阵后,正向运行时每步只需要一次矩阵乘法就能算出最优控制量。
核心收获:
- Backward pass + Forward simulate 的"双向"结构,是后续 iLQR 和 AL-iLQR 的核心骨架
- LQR 反馈增益 的求解方式(Riccati 递推),将在 iLQR 中以几乎相同的形式出现